

📣 一、简介
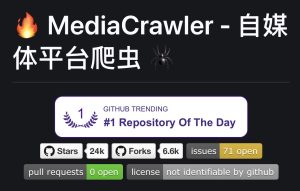
MediaCrawler 是一款开源且功能强大的多平台内容爬虫神器,由 NanmiCoder(Relakkes)开源,主打“全平台数据一键采集”。从小红书、抖音、快手,到 B站、微博、百度贴吧、知乎,主流平台全覆盖 (GitHub)。
其核心是基于 Playwright 浏览器自动化,保留登录态,通过 JS 表达式获取签名参数,无需复杂逆向,就能稳定拿到数据 (GitHub)。
✨ 二、亮点
- 多平台覆盖:支持关键词搜索、帖子详情、创作者主页、评论(含二级评论)、评论词云、点赞与转发信息等 (GitHub)。
- 统一格式输出:导出 JSON、CSV、Excel,数据整齐一致,方便下游分析。
- 稳定机制:自动登录态缓存、IP 代理池支持(Pro 版提供更强 IP/多账号机制) (GitHub)。
- 易扩展开发:模块化结构,自定义平台模块开发简单,上手快。
- 社区活跃:GitHub 上数万 Star,issue 讨论频繁,问题响应迅速 (CSDN博客, CSDN博客)。
| 平台 | 关键词搜索 | 指定帖子ID爬取 | 二级评论 | 指定创作者主页 | 登录态缓存 | IP代理池 | 生成评论词云图 |
| 小红书 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 抖音 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 快手 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| B 站 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 微博 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 贴吧 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 知乎 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
🧰 三、技术栈
- Python 作为主力语言
- Playwright 实现浏览器自动化,保留登录上下文,避免 JS 签名逆向 (GitHub)
- Node.js 驱动部分平台签名及环境支持(版本 ≥16)
- uv 管理 Python 环境(推荐)
- SQLite/MySQL/CSV/Excel 用于本地数据存储或导出
💻 四、部署 & 运行方式
1. 环境准备
Tips:使用ai编辑器帮你运行效率更加
- 安装
uv管理环境,并根据文档验证:
curl -LsSf https://astral.sh/uv/install.sh | sh
uv --version2. 代码 & 依赖安装
- 安装 Node.js(≥16)
git clone https://github.com/NanmiCoder/MediaCrawler.git
cd MediaCrawler
uv sync3. 浏览器环境安装
uv run playwright install4. (可选)虚拟环境
若不使用 uv:
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
playwright install▶️ 五、使用方式
📌 基本命令
uv run main.py --platform xhs --lt qrcode --type search或:
python main.py --platform xhs --lt qrcode --type search参数说明:
--platform:目标平台(如 xhs、小红书;dy、抖音 等)--lt:登录方式(qrcode 二维码登录,phone 手机,cookie)--type:爬取类型(search 关键词、detail 帖子详情、creator 创作者主页)
运行时程序会弹出二维码,扫码登录后自动爬取。
若需开启评论爬取,可编辑 config/base_config.py,将 ENABLE_GET_COMMENTS = True 并配置 IP 代理池。
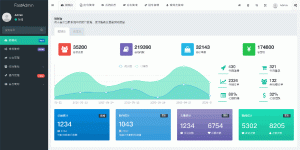
![图片[1]-33KStars!开源爬虫工具MediaCrawler:全平台数据采集神器](http://img.seekresource.com/img/12257)
数据采集截图
⚙️ 高级功能突破
- 支持多平台联合爬取,只需配置
platforms = ['xiaohongshu','douyin']和关键词即可 - 数据输出支持 CSV、JSON、Excel,可依据环境轻松切换
- 代码结构模块化,支持用户轻松添加其他平台支持
✅ 六、注意事项
本项目仅限 学习研究、内容分析,严禁商业用途或大规模爬取,避免法律风险 (GitHub, GitHub)
平台频繁升级反爬机制,需要搭建代理池、控制请求频率、防止 IP 被封
尊重平台版权与隐私,合理使用采集内容
💻七、大实战场景
1. 舆情监控
实时抓取品牌相关评论,分析用户情感倾向(如负面关键词预警)
2. 竞品分析
对比抖音/快手同类视频的互动数据,优化内容策略
3. 热点追踪
通过微博/知乎评论挖掘社会热点,生成传播路径图谱
4. 学术研究
分析小红书美妆类笔记评论,构建用户偏好模型
5. 商业情报
爬取B站科技类视频弹幕,统计技术关键词热度趋势
6. 内容风控
自动检测贴吧/论坛中的违规言论,构建审核规则库
🧩 八、总结
MediaCrawler 是一款“小白友好、功能全能”的爬虫工具,适合运营、竞品分析、内容研究等多种场景使用。无需深入逆向,只需扫码登录,即可一键获取全平台公开数据。
如果你想快速搭建内容采集体系,或了解跨平台爬虫实战,MediaCrawler 是值得收藏的开源工具!
⭐九、项目地址
⭐ 开源不易,有用记得给个 Star 支持下:
看完不过瘾,那就自己发一篇吧!© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END







![表情[nanguo]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/nanguo.gif)
![表情[haobang]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/haobang.gif)
![表情[shuai]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/shuai.gif)
![表情[deyi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/deyi.gif)
![表情[chi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/chi.gif)



暂无评论内容