

龙哥推荐理由
这篇论文简直是“穷玩”机器人的福音!它没有堆砌复杂的算法,而是用最朴素的思路,在极致的硬件限制下(ESP32单片机),实现了端到端的实时自动驾驶。整个项目从硬件选型、数据采集、模型设计到部署优化,形成了一个非常完整的闭环,复现门槛低,工程价值极高。对于想入门嵌入式AI、机器人导航的同学来说,这是一个绝佳的实践范本。
原论文信息
论文标题
TinyNav: End-to-End TinyML for Real-Time Autonomous Navigation on Microcontrollers
发表日期
2026年03月
发表单位
Queen’s University (女王大学)
原文链接
开源代码
开源数据集
包含在代码仓库中
微控制器上的自动驾驶?TinyNav打破你的认知
用20块钱的单片机搞自动驾驶?这听起来像是天方夜谭,但女王大学的一群学生真的做到了。
在过去,要让一个小机器人自己跑起来不撞墙,你大概需要一块树莓派,配上复杂的SLAM(即时定位与地图构建)算法,或者至少得有个像样的迷你电脑。但你想过吗,也许我们一直以来都把问题想复杂了。
这篇名为 TinyNav 的论文,提出了一种极简主义的思路:抛弃所有复杂的建图和规划,让机器人像生物一样,仅凭“眼睛”(深度摄像头)看到的东西,直接反应出“手脚”(转向和油门)的动作。最关键的是,这个“大脑”小到可以塞进一块成本仅约20美元的ESP32微控制器里。
这背后是 TinyML (Tiny Machine Learning, 微型机器学习) 的理念在闪光。TinyML的目标就是把AI模型塞进资源极其有限的微控制器、传感器里,实现本地、实时、低功耗的智能。而TinyNav,就是TinyML在自主导航领域一个非常漂亮且务实的落地案例。
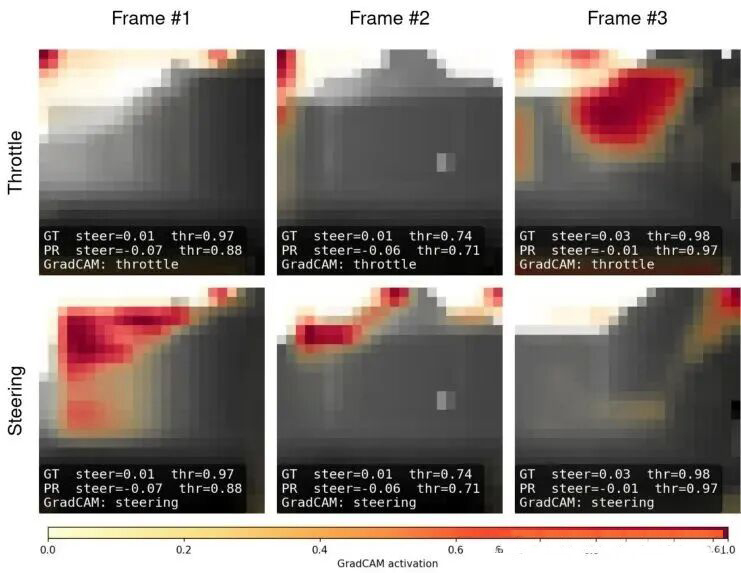
图7:Steering & Throttle activation examples
轻装上阵:仅23k参数的导航大脑如何炼成
在只有 32MB RAM 和 几百KB 高速缓存的ESP32上跑神经网络,就像在老爷车上装F1引擎,处处是限制。TinyNav的模型设计,处处体现了“螺蛳壳里做道场”的智慧。
第一个挑战:如何处理时间信息?机器人导航是连续的,需要知道“刚才发生了什么”才能预判。在高端设备上,我们常用LSTM(长短期记忆网络)或3D卷积来处理视频序列。但在微控制器上,这些层要么不支持,要么计算量爆炸。
TinyNav的解决方案简单粗暴又巧妙:把20帧连续的历史深度图,像叠扑克牌一样叠在一起,形成一个20通道的“超级图片”。然后,用一个普通的2D卷积神经网络(CNN)去处理它。虽然2D CNN原本是为单张图片设计的,但当你把时间维度塞进通道维度后,网络就能在卷积过程中,同时“瞟见”不同时间点同一位置的变化,从而隐式地感知到运动趋势和速度。
第二个挑战:模型必须极小。最终定型的网络结构非常精简:输入是24×24像素、20通道的“时空块”,经过几层卷积和池化提取特征,最后通过两个并行的全连接层(一个管转向,一个管油门)输出控制指令。整个模型只有 23,000个参数。作为对比,一个中等大小的图像分类模型参数可能以百万计。
第三个关键步骤:量化。为了让模型在微控制器上跑得更快、更省内存,量化是必不可少的。简单说,就是把模型权重和计算从浮点数(如32位)转换成整数(如8位)。TinyNav使用了TensorFlow Lite Micro框架内置的后训练量化,将模型转换为INT8格式。
结果非常惊人:量化后的模型在验证集上,转向精度保留了原模型的99.84%,油门精度保留了99.79%。这意味着几乎没损失性能,却换来了巨大的内存和速度收益。最终,这个量化后的23k参数模型在ESP32上跑一次推理(即处理20帧数据并做出决策)只需要 30毫秒,完全满足实时控制的要求。
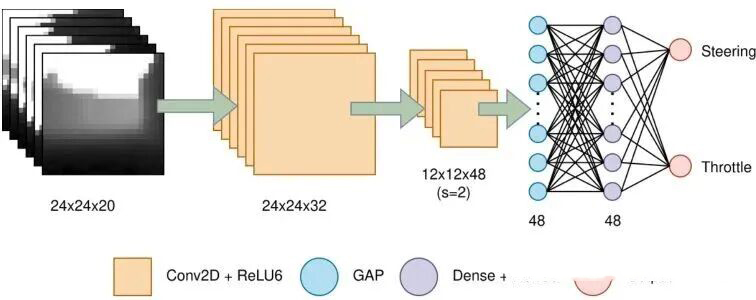
图3:TinyNav的模型架构。输入是20帧堆叠的深度图,经过2D CNN处理,最终输出转向和油门两个控制值。
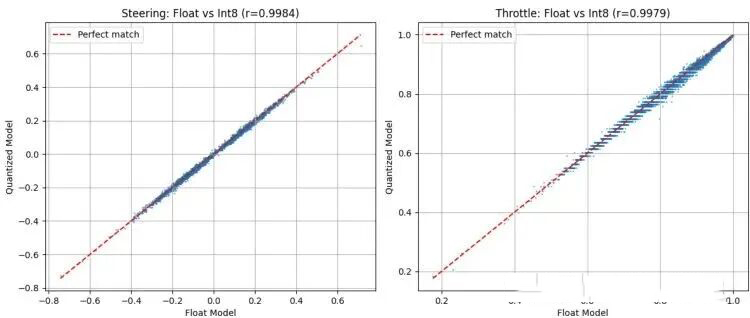
图4:量化前后模型输出的相关性。左图为转向输出,右图为油门输出。点越集中在对角线上,说明量化误差越小。可以看到,INT8量化模型(红点)的输出与原始浮点模型(蓝点)的输出高度一致。
从数据到部署:一个务实TinyML项目的完整闭环
一个好模型离不开好数据,而TinyNav的数据收集和工程部署流程,堪称嵌入式AI项目的教科书式范例。
硬件选型:够用就好
核心是 ESP32-P4微控制器 和 Sipeed MaixSense A010 ToF深度摄像头。ToF是Time-of-Flight的缩写,即飞行时间法。它通过发射红外光并测量光线反射回来的时间,直接计算出物体到摄像头的距离,生成深度图。这种传感器数据规整,比普通RGB摄像头更容易让模型理解空间结构。作者还将摄像头原始的100×100分辨率在传感器端进行了4×4的合并(Binning),降为25×25,进一步减少了数据量。
数据收集:自己动手,丰衣足食
他们没有使用现成的仿真数据集,而是搭建了一个实体赛道,用人手遥控小车跑圈,同时记录下每一刻摄像头看到的深度图,以及此刻操作者给出的转向和油门指令。这就构成了一个“图像-动作”配对的数据集。他们特意改变了赛道的布局(宽窄、弯道)、地面材质,让数据尽可能多样。

图2:用于数据收集的赛道俯视图示例。由可移动的墙板组成,可以变换不同布局。
系统工程:双核并行的智慧
为了让30ms的推理延迟不影响整体控制的流畅性,他们利用了ESP32的双核架构:一个核心专责运行AI模型进行推理;另一个核心负责控制循环,收集传感器数据、发送电机指令。两个核心通过共享内存来交换最新的20帧图像窗口和推理结果。这样,即使某次推理偶尔慢了一点,控制循环也不会被卡住,确保了系统的实时响应。
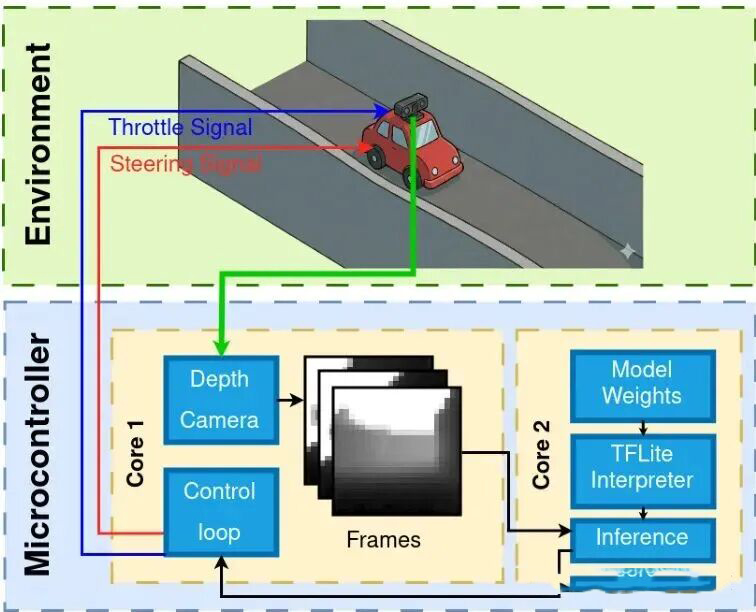
图1:TinyNav的实时自主导航流水线。展示了从深度摄像头数据采集、20帧滑动窗口构建、CNN模型推理到双核并行处理控制指令的完整流程。
效果如何?看小车在迷宫中稳健穿梭
光说模型小、推理快没用,关键是跑起来怎么样。TinyNav的验证工作做得很扎实。
定量分析:预测准不准?
图5展示了模型预测的转向、油门值与真实驾驶员操作(Ground Truth)之间的相关性。虽然点没有完全落在对角线上(完美预测),但呈现出了清晰的线性趋势。转向和油门的预测与真值的相关系数约为0.6,对于一个23k参数的模型而言,这已经是一个相当不错的结果,表明模型确实学到了有效的映射关系,而不是胡乱输出。
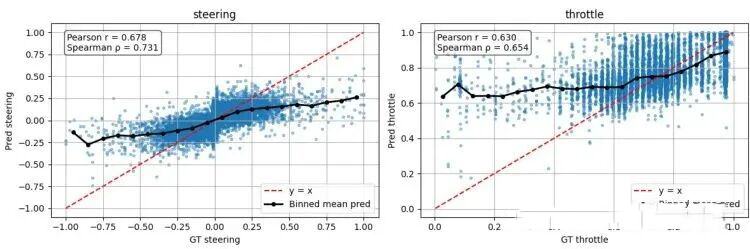
图5:转向与油门预测值与真实值的相关性图。灰色散点为每个样本的预测,红色线段为分箱后的均值趋势线,可以看出明显的正相关关系。
图6则对比了预测值和真实值的分布。可以看到,两条曲线高度重合,这意味着模型输出的控制指令在统计分布上与人类驾驶员相似,没有出现“回归到均值”的懒惰行为(比如永远输出转向为0或固定油门),而是能够做出从直行到急转弯、从全速到刹车的全范围决策。
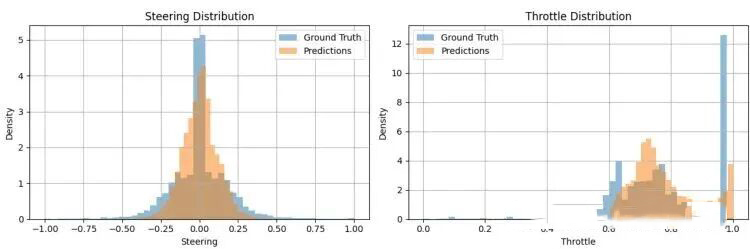
图6:真实值与预测值的概率分布对比。蓝色为真实值分布,橙色为模型预测值分布,两者基本吻合。
定性分析:模型在看哪里?
为了理解这个“黑箱”模型是如何做决策的,作者使用了 Grad-CAM(梯度加权类激活映射)技术进行可视化。Grad-CAM能够生成一张“热力图”,高亮显示输入图像中对网络决策影响最大的区域。
从图7可以看到一些有趣的模式:
转向头(Steering Head)经常关注图像上方的区域(对应赛道墙的顶部边缘)。这是因为在简单的赛道环境中,上方的边缘是区分通道和墙壁最清晰、最稳定的特征。
油门头(Throttle Head)则表现出更情景化的关注点:在直道可能关注前方开阔区域,在死胡同或弯道则会关注迫近的墙壁,从而决策减速。这证明模型确实学会了根据环境结构来调节速度,而不仅仅是死记硬背。
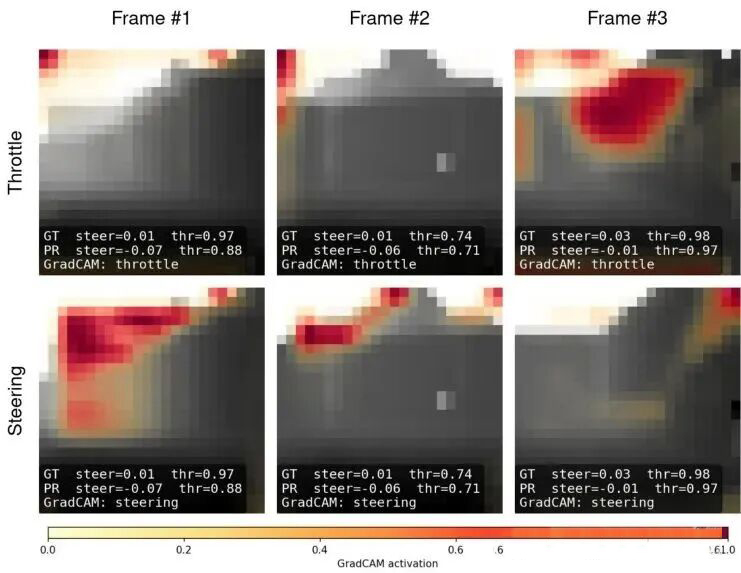
图7:Grad-CAM可视化示例。左侧为原始深度图,中间为转向决策的激活区域(关注上方边缘),右侧为油门决策的激活区域(在死胡同关注正前方的墙以减速)。
实地测试:跑得稳不稳?
在实际赛道中,装配了TinyNav的小车在训练过的赛道布局上可以连续完成40圈而不发生碰撞。在未见过的、更复杂的布局上,它也能完成全程,尽管偶尔会有轻微的刮蹭。油门控制也表现出智能性:长直道上加速,接近弯道或死胡同时平滑减速。这表明端到端的学习方式成功地将视觉感知转化为了合理的连续控制策略。
局限性明显,但未来可期:TinyML导航的挑战与机遇
当然,TinyNav作为一个学术原型系统,局限性也非常明显。论文作者们对此非常坦诚,这些局限恰恰指明了TinyML在机器人导航领域的未来发展方向。
1. 模型能力天花板低:23k参数是优势也是束缚。这意味着它无法学习非常复杂的场景和精细的控制策略。论文提到,ESP32这类设备能流畅运行的模型参数上限大概在5万左右,这严重限制了算法的表达能力。
2. 数据集单一,泛化能力弱:训练数据全部来自结构相似的室内矮墙赛道。模型没见过椅子、行人、台阶、户外复杂光影,因此几乎不可能直接泛化到这些场景。要提升泛化能力,需要收集极其多样化的数据,这本身就是一个巨大挑战。
3. 缺乏状态反馈,容易“漂移”:小车没有安装轮子编码器,因此模型不知道轮子实际转了多少、车子有没有打滑。它纯粹基于视觉特征来决策,在低纹理地面或连续相似场景中,容易产生累积误差,导致“漂移”。增加低成本的编码器反馈,构建一个简单的内部状态估计,是未来改进的重要方向。
4. 仅支持前向行驶:倒车对于这个模型来说太复杂了,因为倒车动力学完全不同,且训练数据中没有包含。要实现全向移动,需要重新设计和收集数据。
尽管有这些局限,TinyNav的价值在于它清晰地证明了一条可行的技术路径:在极端资源限制下,通过精心设计的端到端学习,实现基本、可用的自主导航能力。这对于成本敏感的教育机器人、特定场景的工业巡检小车、智能玩具等领域,具有 immediate 的启发和参考价值。未来的工作可以围绕更高效的网络架构设计、仿真到实物的迁移学习、多传感器融合等方向展开。
龙迷三问
下面是龙哥对于大家可能的一些问题的解答:
什么是TinyML?它和普通的AI模型有什么区别?TinyML,全称Tiny Machine Learning,即微型机器学习。它的核心目标是将机器学习模型部署到资源极其有限的边缘设备上,如微控制器(MCU)、传感器等。与在云端或强大GPU上运行的普通AI模型相比,TinyML模型需要经过极致的压缩(如剪枝、量化),模型规模小(常为KB级别),计算量极低,以实现低功耗、低成本、低延迟和隐私保护的本地实时推理。TinyNav就是TinyML在自主导航领域的一个典型应用。
ToF深度摄像头是如何工作的?为什么用它而不用普通摄像头?ToF(Time-of-Flight)摄像头通过发射调制过的红外光脉冲,并测量每个像素点接收反射光所需的时间,直接计算出物体到摄像头的距离,生成一幅深度图(每个像素值代表距离)。相比普通RGB摄像头,深度图提供了直接的三维空间信息,避免了从2D图像推断3D结构的复杂性和歧义性,对于避障和导航任务来说,输入信息更“干净”、更直接,因此模型可以更小、更高效。
为什么模型只有23k参数,却还能工作?端到端学习是什么?模型小却能工作,得益于两点:一是任务简化(结构化室内避障),输入(深度图)和输出(转向/油门)高度相关;二是采用了端到端(End-to-End)学习。传统导航系统通常分为感知、建图、规划、控制等多个模块,每个模块都很复杂。端到端学习则用一个单一的神经网络,直接从原始传感器数据映射到控制指令,省去了中间模块的设计和误差累积。虽然单个模型能力有限,但在特定任务上,这种“直觉式”反应往往更高效。TinyNav的模型就是一个典型的端到端控制器。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~
龙哥点评
论文创新性分数:★★★☆☆
思路清晰但非革命性。将时间堆叠通道的2D CNN用于微控制器导航是一个实用且巧妙的设计,但核心的端到端思想和TinyML框架属于现有技术的组合应用。
实验合理度:★★★★☆
实验设计非常完整和务实,从数据收集、模型训练、量化验证到Grad-CAM可解释性分析和实物测试,形成了一个可信的闭环。没有与SOTA进行不公平的对比(因为场景不同),而是专注于证明自身方案在限定条件下的可行性。
学术研究价值:★★★☆☆
为资源极度受限的自主导航提供了一个清晰、可复现的工程范本和研究基线。其价值更多体现在工程实践和教育意义上,推动了TinyML在机器人领域的落地思考,而非理论上的重大突破。
稳定性:★★☆☆☆
在训练场景类似的简单结构化环境中表现稳定,但泛化能力弱,对数据分布之外的新障碍、光照变化、地面打滑等情况非常脆弱,容易失效或碰撞,距离产品化要求的鲁棒性有较大差距。
适应性以及泛化能力:★☆☆☆☆
如前所述,高度依赖于特定的训练环境(矮墙赛道)。几乎无法适应任何未在训练数据中出现过的场景、障碍物类型或运动模式(如倒车),泛化能力是其最大短板。
硬件需求及成本:★★★★★
这是本文最大的亮点。硬件成本极低(约20美元的主控),计算资源需求极小(23k参数,30ms推理),功耗低,完美符合TinyML和边缘计算的理念,在成本敏感的应用中优势巨大。
复现难度:★★★★★
作者提供了完整的代码、模型、数据集、硬件物料清单(BOM)和详细文档,复现门槛极低,对爱好者、学生和研究者非常友好,极大地提升了论文的实用价值。
产品化成熟度:★☆☆☆☆
目前仅为一个研究原型。要产品化,必须解决泛化能力弱、缺乏状态反馈、仅支持前向行驶等核心问题。可能适用于某些高度可控、环境固定的特定工业或玩具场景,但需要大量额外的工程优化和场景适配。
可能的问题:本文更像一个优秀的工程项目报告或高级课程设计,其学术深度和创新性有限。实验结果虽能自洽,但未在更广阔、更标准的机器人导航测试集上进行评估,其性能上限和局限性更多是定性和推断。
主要参考文献
[1] R. David et al., “Tensorflow lite micro: Embedded machine learning on tinyml systems,” arXiv preprint arXiv:2010.08678, 2021.
[2] Espressif Systems, “Esp-nn: Optimised neural network functions for espressif chipsets,” GitHub repository, 2026.
[7] R. R. Selvaraju et al., “Grad-cam: Visual explanations from deep networks via gradient-based localization,” arXiv preprint arXiv:1610.02391, 2016.
*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的”阅读原文”,查看更多原论文细节哦!
来自:龙哥读论文
原创:驭龙机甲
看完不过瘾,那就自己发一篇吧!







![表情[nanguo]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/nanguo.gif)
![表情[haobang]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/haobang.gif)
![表情[shuai]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/shuai.gif)
![表情[deyi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/deyi.gif)
![表情[chi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/chi.gif)



暂无评论内容