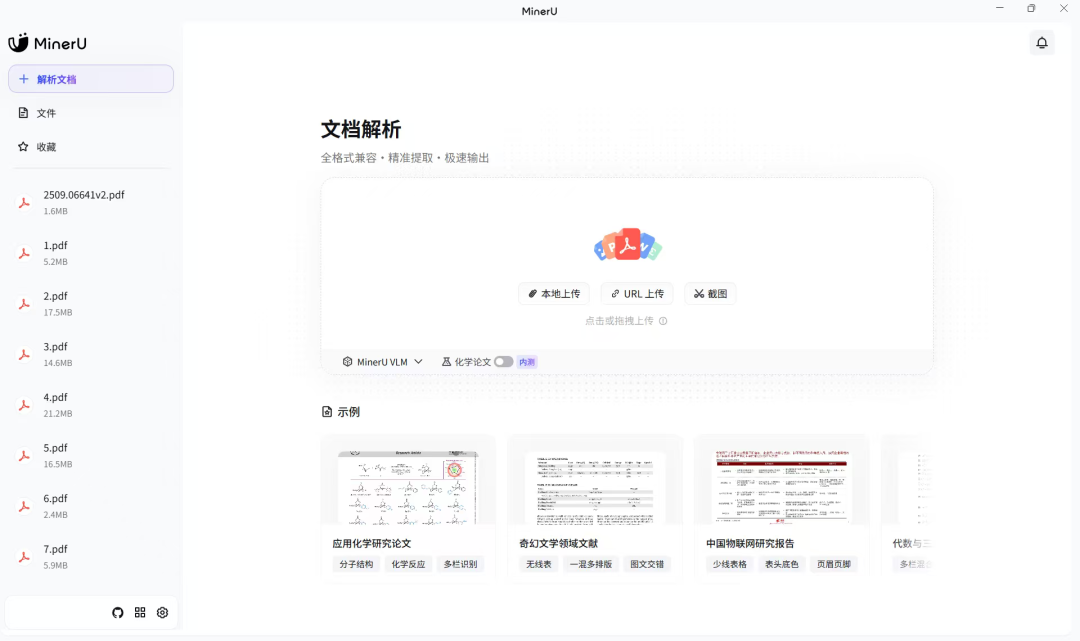

需求来源
昨晚23点的时候,我要整理一份200多页的行业报告。
对PDF解析完后,我彻底傻眼了:文档里面的表格和公式都乱了,根本看不下去!
后面我前前后后换了三个PDF转换工具,要么就是表格还是乱的,要么就是公式变成了乱码。
有个付费工具更让我无语,它居然能将一个三栏布局的文档,按照从左到右的顺序给拼接了起来!离谱至极!
最后我还是从github上找到一个开源项目才解决了这个问题。
这个项目叫MinerU,现在已经有44.1k star了。
性能表现
先来说一下解析速度。
最快能达到10000+ tokens/s。
什么概念?
我给你举个例子,如果你拿一本300页的技术文档丢进去,几分钟它就能给你搞定!(不同设备有差异)
![图片[2]-44.1k star!小参数大模型一键解析PDF,彻底解决文档提取难题!-寻找资源网](http://img.seekresource.com/img/12583)
运行条件
MinerU的门槛也不高,就算你用的是6GB的显卡也一样能跑起来。
最让我惊喜的是MinerU对格式的理解能力。
无论是复杂的数学公式还是那种跨页的大表格,甚至连那种左一栏右一栏的学术论文对它来说都不是问题,它都可以准确识别并转换成你想要的格式。
![图片[3]-44.1k star!小参数大模型一键解析PDF,彻底解决文档提取难题!-寻找资源网](http://img.seekresource.com/img/12584)
测试表现
为了测试它的能力,我拿了一篇包含大量LaTeX公式的关于机器学习的论文丢了进去,这种论文平时我看都不想看的,结果MinerU居然将所有公式都完美还原成LaTeX格式了!
对于学生来说这个东西真的太棒了,直接就能复制黏贴进论文里面使用。
我看了一下介绍,介绍中说MinerU的核心是用了多模态深度学习技术,用大白话说就是:MinerU不是简单识别文字内容,而是真正“理解”了文档的结构。
如果是传统的工具,要是你拿一个表格给它处理,它一般就只会傻乎乎的按行读取。
但MinerU不同,它会先识别这个到底是啥,知道是表格后它会分析表头、理解单元格之间的关系,最后再给你生成一个完整的HTML表格。
格式的问题就完美的解决了!
经常接触文档的人都知道,页眉页脚这些东西看似很简单但烦人得很,MinerU也贴心的帮你搞定了。
MinerU可以自动识别页眉页脚并移除,还能对脚注进行处理,保持阅读的顺序。
再来聊一下MinerU的OCR。
MinerU内置的OCR支持84种语言,从中文到阿拉伯文,从日文到希伯来文,统统不在话下。而且根本不需要你动手选择,它会自动识别是否需要OCR。
我试过将一份20年前的扫描版合同丢给它,识别率差不多达到了95%,有些模糊的手写批注它都识别出来了!
转换完成后,就到输出格式了,你可以选择markdown、JSON、或者给开发者用的中间格式,可以自定义处理流程。
![图片[4]-44.1k star!小参数大模型一键解析PDF,彻底解决文档提取难题!-寻找资源网](http://img.seekresource.com/img/12585)
MinerU还提供可视化结果,你可以直观的看到哪些地方识别出来了,哪些地方不太行。
如果你也经常需要处理文档,MinerU绝对值得你试一试。
三种模式
- 简单模式:CPU就能跑,6GB显存起步,日常使用就够了。
- 普通模式:需要8GB+显存,适合处理复杂的文档。(我现在使用的就是这个)
- 地狱模式:那就是大佬们用的了,推理速度起飞,但对硬件要求也很高。
感兴趣可以看一看。







![表情[nanguo]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/nanguo.gif)
![表情[haobang]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/haobang.gif)
![表情[shuai]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/shuai.gif)
![表情[deyi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/deyi.gif)
![表情[chi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/chi.gif)



暂无评论内容