
排序
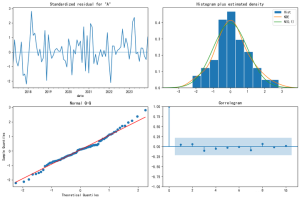
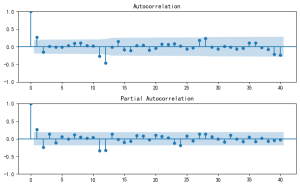
【Python数据分析案例(2025)】12——基于SARIMA的AQI空气质量预测
SARIMAX模型在预测AQI方面显示出前景。但是,不显著系数的存在表明可以简化模型。仅使用显著系数(移除ma.L1、ar.S.L12、ma.S.L12、ma.S.L24)重新运行模型可能会提高模型的简约性和预测精度。...


【Python自动化案例】02——获取中国高校排名数据排名有名次,各有所长自行选择。
爬取这个网站所有的高校的数据,包括学习名称,层次,地区,分数等等信息:['办学层次','学科水平','办学资源','师资规模与结构','人才培养','科学研究','服务社会','高端人才','重大项目与成果...
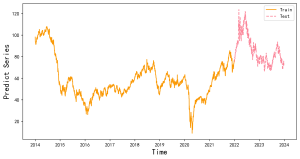

【Python数据分析案例(2025)】14——基于神经网络的时间序列预测(滞后性的效果,预测中存在的问题)回顾多个案例
这篇文章可以说是基于 现代的一些神经网络的方法去做时间序列预测的一个介绍科普,也可以说是一个各种模型对比的案例,但也会谈一谈自己做了这么久关于神经网络的时间序列预测的论文,其中一些...
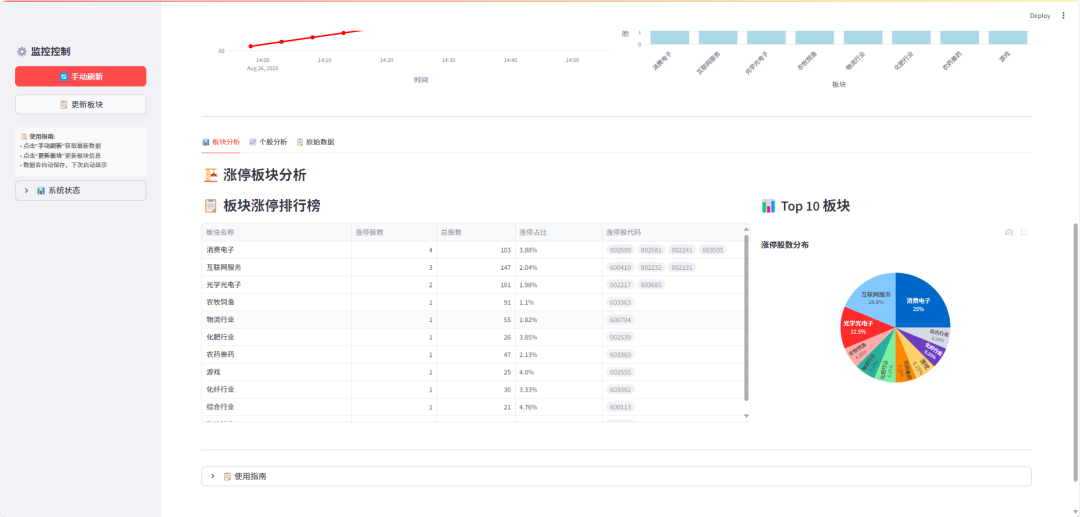
别错过涨停!Python打造A股实时监控大屏
作者:派晓生来自:量子云智侠之前有粉丝在后台留言说: 👉 “能不能写一个 涨停监控工具?每天涨停板太多,想随时能看。”于是我写了这款 A股涨停监控系统(网页版),今天完整开源分享给大...

33KStars!开源爬虫工具MediaCrawler:全平台数据采集神器数字媒体
MediaCrawler 是一款开源且功能强大的多平台内容爬虫神器,由 NanmiCoder(Relakkes)开源,主打“全平台数据一键采集”。从小红书、抖音、快手,到 B站、微博、百度贴吧、知乎,主流平台全覆盖...
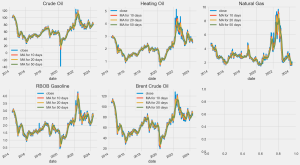
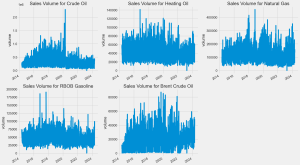
【Python数据分析案例(2024)】(44)——基于EEMD-LSTM的石油价格预测神经网络模型
很久没更新时间序列预测有关的东西了。 之前写了很多CNN-LSTM,GRU-attention,这种神经网络之内的不同模型的缝合,现在写一个模态分解算法和神经网络的缝合。 虽然eemd-lstm已经在学术界被做烂...

Python高效办公:1.4秒自动填充900+题库答案,告别手动复制粘贴!(附件可下载)
前言你是否遇到过把答案复制到题库中对应习题的情形?最近收到一个这样的问题,有一组题库,习题和答案都以docx格式保存。现需要把选项答案填入到对应习题的括号内。先来算笔账:如果手动来填,...

告别树莓派!女王大学用ESP32实现端到端自动驾驶,成本仅百元
龙哥推荐理由这篇论文简直是“穷玩”机器人的福音!它没有堆砌复杂的算法,而是用最朴素的思路,在极致的硬件限制下(ESP32单片机),实现了端到端的实时自动驾驶。整个项目从硬件选型、数据采...
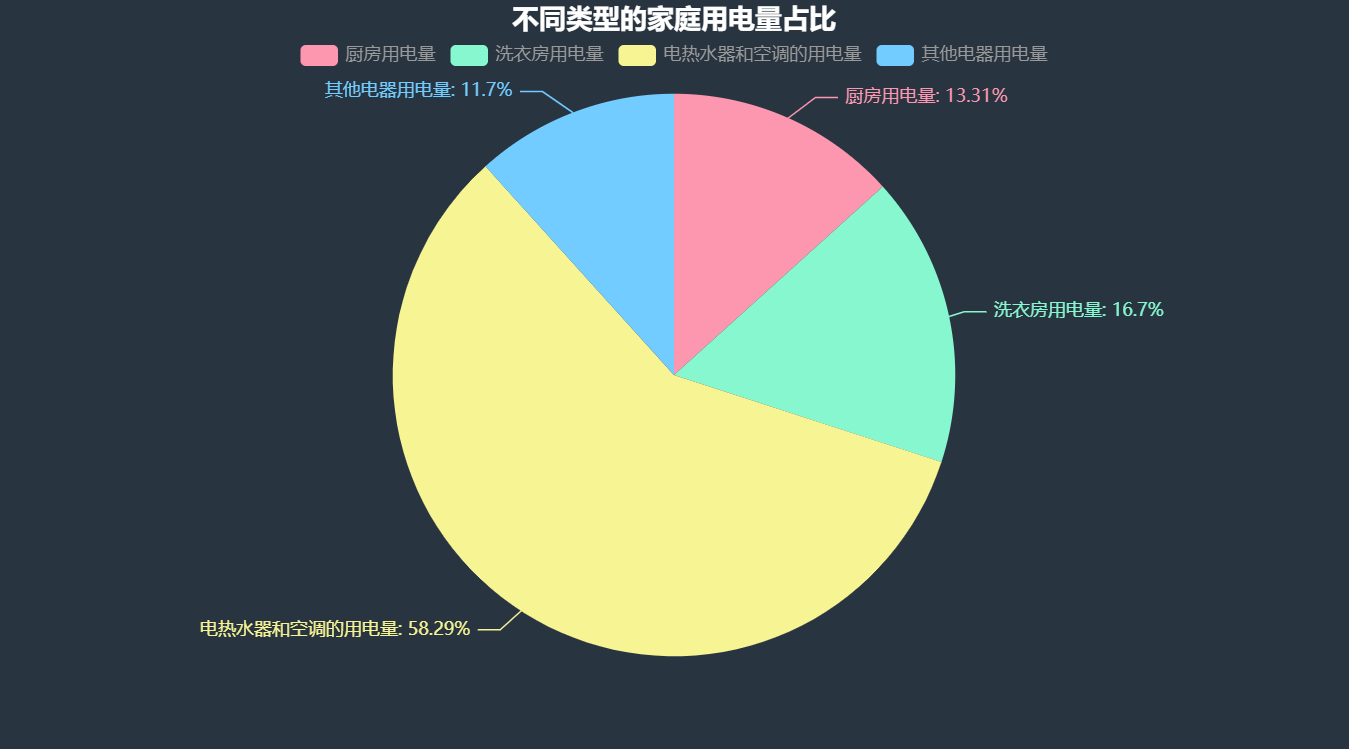
【Python数据分析案例(2025)】29——针对家庭用电数据进行时序分析
1、数据说明本项目所用数据集包含了一个家庭6个月的用电数据,收集于2007年1月至2007年6月。这些数据包括有功功率、无功功率、电压、电流强度、分项计量1(厨房)、分项计量2(洗衣房)和分项计...


【Python数据分析案例(2025)】18——基于内容的深度学习推荐系统(电影推荐)智能推荐值得一看的影片
推荐系统本质上是一种旨在向用户推荐相关项目的系统/模型/算法。它可以是电影、音乐等等。一般来说,当涉及到用户与服务提供商或买家与电子商务之间的关系时,就非常需要推荐。最终良好的推荐将...
广告位



