

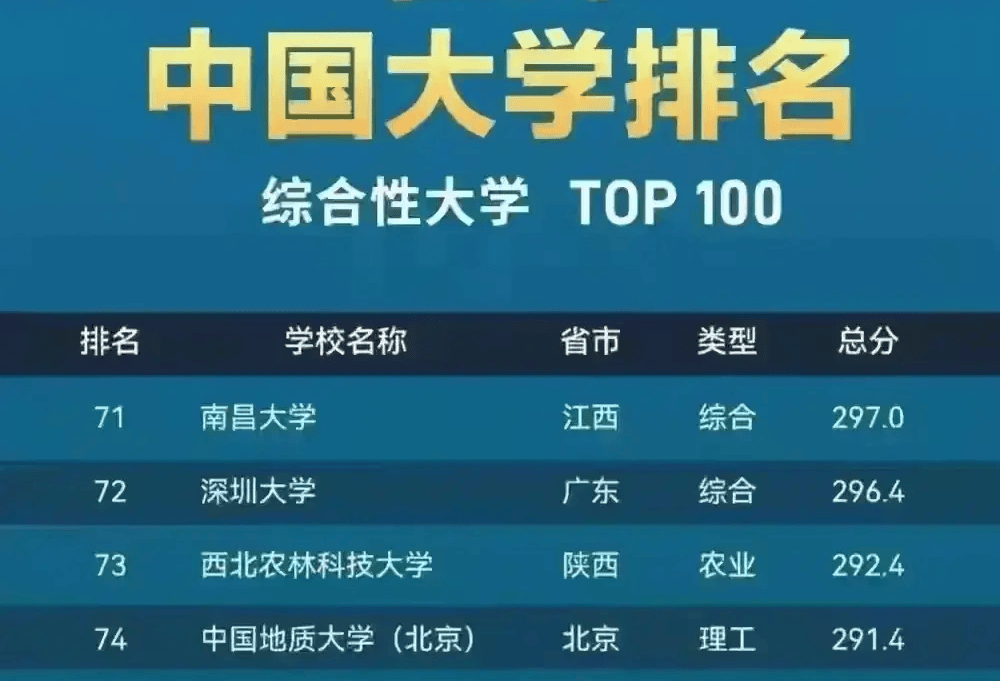

案例背景
【软科排名】2023年最新软科中国大学排名|中国最好大学排名 (shanghairanking.cn)
爬取这个网站所有的高校的数据,包括学习名称,层次,地区,分数等等信息:[‘办学层次’,’学科水平’,’办学资源’,’师资规模与结构’,’人才培养’,’科学研究’,’服务社会’,’高端人才’,’重大项目与成果’,’国际竞争力’]
分析思路
动态网页,没办法用resquest获取网页文件然后bs解析,json接口也没得….只能js动态获取然后清洗,或者selenium库模拟点击。
我这里使用selenium库模拟点击,慢是慢了点,但是能用….
(这是我爬过最麻烦的网站,下面这三个按钮折腾了我好久….换了页就点击不了,一直说有什么遮挡住了,,我只能爬一个项目重启一次浏览器)
![图片[1]-【Python自动化案例】02——获取中国高校排名数据排名有名次,各有所长自行选择。-寻找资源网](http://img.seekresource.com/img/10437)
准备工作
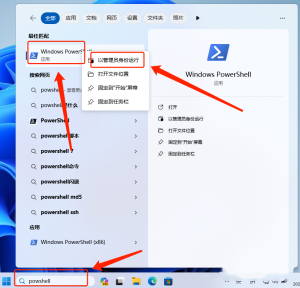
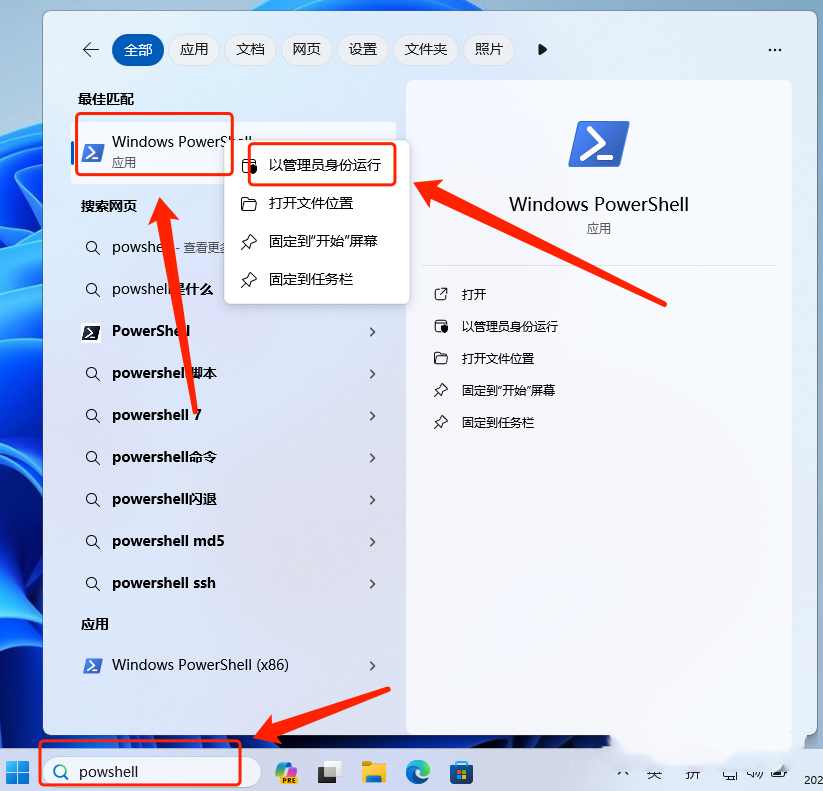
模拟点击selenium库需要一个浏览器驱动程序,
这里用的是edge的驱动器,需要去官网下载:Microsoft Edge WebDriver – Microsoft Edge Developer
![图片[2]-【Python自动化案例】02——获取中国高校排名数据排名有名次,各有所长自行选择。-寻找资源网](http://img.seekresource.com/img/10438)
然后把msedgedriver.exe文件和代码放在一个目录下就能运行了。
编写代码
导入包:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from bs4 import BeautifulSoup
import os
import pandas as pd
from time import sleep
爬虫代码:
url = "https://www.shanghairanking.cn/rankings/bcur/2023"
df_all=pd.DataFrame()
options=['办学层次','学科水平','办学资源','师资规模与结构','人才培养','科学研究','服务社会','高端人才','重大项目与成果','国际竞争力']
for i in range(len(options)):
research_name=options[i]
print(research_name)
#启动浏览器
driver = webdriver.Edge("msedgedriver")
driver.implicitly_wait(2)
driver.get(url)
sleep(2)
#点击选项
bu=driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/thead/tr/th[6]/div/div[1]/div[1]')
bu.click()
fund = driver.find_element(By.XPATH,f'//*[@id="content-box"]/div[2]/table/thead/tr/th[6]/div/div[1]/div[2]/ul/li[{i+1}]')
fund.click()
df_oneresearch=pd.DataFrame()
#遍历20面
for page in range(20):
# 定位到表格元素
table = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody')
data_list = []
rows = table.find_elements(By.TAG_NAME, "tr")[:]
for row in rows:
cells = row.find_elements(By.TAG_NAME, "td")
rank = cells[0].text.strip()
university_name = cells[1].find_element(By.CLASS_NAME, "name-cn").text.strip()
english_name = cells[1].find_element(By.CLASS_NAME, "name-en").text.strip()
tags = ""
#tages = cells[1].find_element(By.CLASS_NAME, "tags").text.strip()
try:
tags = cells[1].find_element(By.CLASS_NAME, "tags").text.strip()
except Exception as e:
pass
#print(f'{university_name}报错了')
location = cells[2].text.strip()
category = cells[3].text.strip()
score = cells[4].text.strip()
research = cells[5].text.strip()
data_dict = {"排名": rank,"中文名)": university_name,"英文名": english_name,"层次标签" : tags, "省市":
location,"类型": category,"总分": score,research_name: research}
data_list.append(data_dict)
df_one=pd.DataFrame(data_list)
df_oneresearch=pd.concat([df_oneresearch,df_one],axis=0,ignore_index=True)
print(f'{page+1}页爬取完成')
# 定位到下一页的元素
next_page_element = driver.find_element(By.CLASS_NAME, "ant-pagination-next")
next_page_element.click()
for col in df_oneresearch.columns:
df_all[col]=df_oneresearch[col]
print('2s后关掉浏览器开始下一个')
sleep(2)
driver.quit()
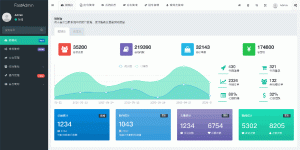
查看:
df_all.head()![图片[3]-【Python自动化案例】02——获取中国高校排名数据排名有名次,各有所长自行选择。-寻找资源网](http://img.seekresource.com/img/10439)
当然获得的数据用下面储存就行了:
df_all.to_excel('高校数据.xlsx',index=False)© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END







![表情[nanguo]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/nanguo.gif)
![表情[haobang]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/haobang.gif)
![表情[shuai]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/shuai.gif)
![表情[deyi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/deyi.gif)
![表情[chi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/chi.gif)



暂无评论内容