
排序
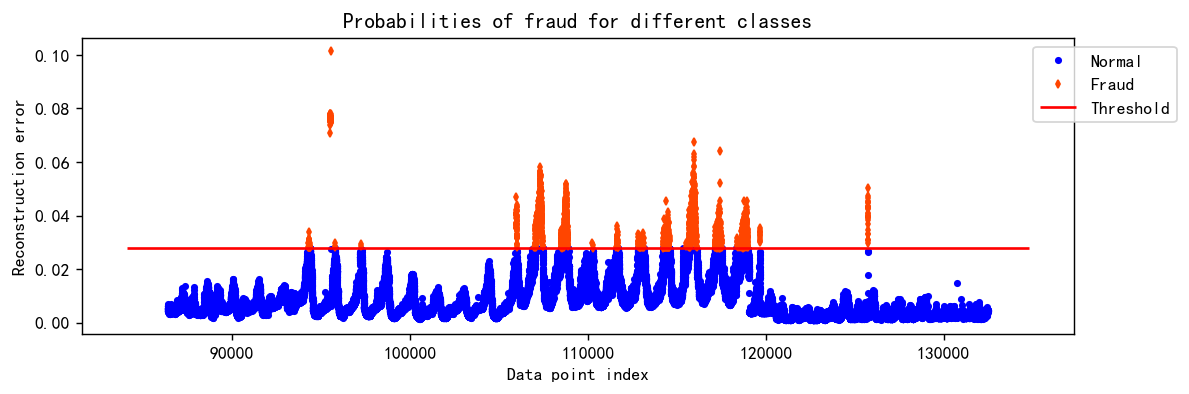
【Python数据分析案例(2024)】49—基于LSTM结构自编码器的多变量时间序列
网盘截屏获取全部源码和数据,请点击“支付下载”,或可前往微信小程序碰碰运气哦,搜索微信小程序“众嗅博客”。支付后没有数据和源码,请联系我们,QQ:1919588043(微信同号)。案例背景时间...
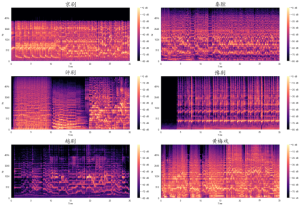
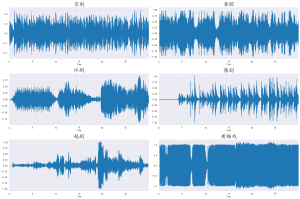
【Python数据分析案例(2025)】10——基于深度学习的音频文件分类(音频文件特征提取和模型构建)深度学习戏剧音频特征提取
每个文件夹里面都有100首MP3歌曲文件。我们就取:“京剧 越剧 黄梅戏 秦腔 豫剧 评剧 ”6个文件夹里面的歌曲吧。 我们要做的就是对这个600首歌曲提取特征,然后进行神经网络的模型训练和分类评...
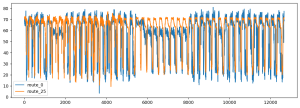
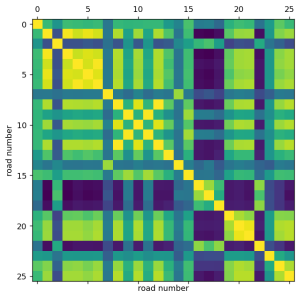
【Python数据分析案例(2025)】19——基于图神经网络的交通路段流量时间序列预测
简单来说,这是一个比较粗糙的案例,主要是演示图结构的LSTM等模型的时间序列预测。没有我之前的那些普通的循环神经网络的案例那么高度封装以及那么完善的评估体系和标准画图方法。 因为之前都...
【Python数据分析案例(2024)】(47)——基于学校学历、岗位技能的工资区间预测(机器学习全模型)
总体而言,这个区间还是挺可以进行参考的,虽然它的范围有点大,但是基本上真实的数值还是能够落入这个区间的。应届生的同学可以用这个程序,输入自己的真实情况以及自己想干的岗位和一些自己的...
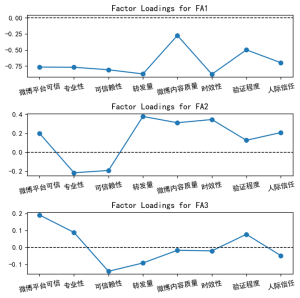
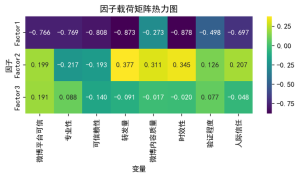
【Python数据分析案例(2025)】11——因子分析回归分析社交平台可信度分析
线性回归,主成分回归都做烂了,我之前的案例有很多这些模型,但是一直没写因子分析的回归案例,这个也是传统统计学流行的方法,在金融经济心理学等人文社科用得非常多。这个案例就演示一下pyth...
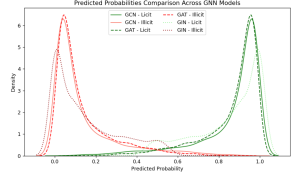
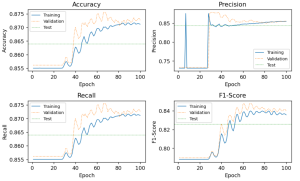
【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别fraud
在欺诈识别这个二分类任务中,三种神经网络模型各有特点。GCN模型的准确率、召回率和 F1 分数分别为 0.835509、0.835509、0.847082,在这三个指标上表现均衡且整体较优,能较好地识别欺诈情况,...
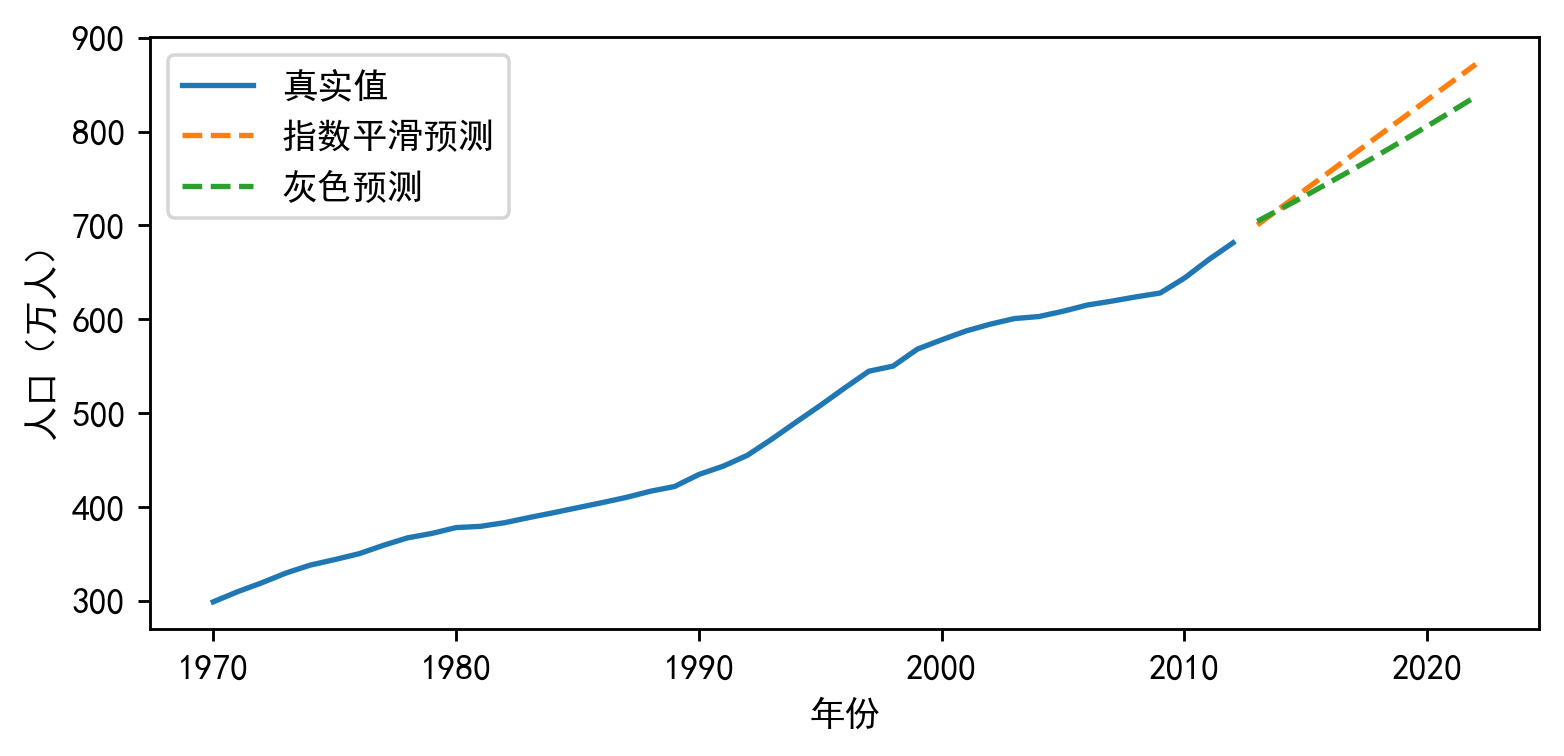
【Python数据分析案例(2024)】50——灰色预测、指数平滑预测人口数量,死亡率,出生率等
网盘截屏支付后获取全部源码和数据,如有疑问请联系我们QQ客服:1919588043(微信同号)。优先QQ。案例背景时间序列的预测现在都是用神经网络,但是对于100条以内的小数据集,神经网络,机器学...
【Python数据分析案例(2024)】(46)——基于SSA-LSTM的风速预测(麻雀优化)
在这个案例里面的,SSA-LSTM效果好于GRU好于LSTM和attention-LSTM,说明优化算的效果是可以的,当然同学们还有时间可以用SSA-GRU,SSA-attention-LSTM都去试试,,看谁的效果好。模型修改就该bu...
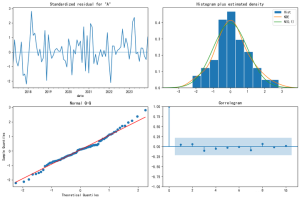
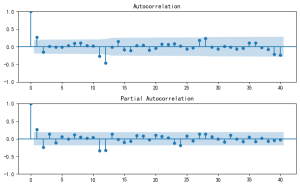
【Python数据分析案例(2025)】12——基于SARIMA的AQI空气质量预测
SARIMAX模型在预测AQI方面显示出前景。但是,不显著系数的存在表明可以简化模型。仅使用显著系数(移除ma.L1、ar.S.L12、ma.S.L12、ma.S.L24)重新运行模型可能会提高模型的简约性和预测精度。...
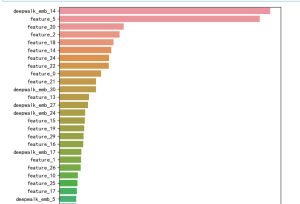
【Python数据分析案例(2025)】22——基于机器学习的餐厅评论反欺诈识别fraud
该数据集由Dou等人引入,用于增强基于图神经网络的欺诈检测器,以识别伪装欺诈者。数据集包含Yelp评论,具有标签(是否欺诈)和32个归一化特征作为属性,以及评论之间的关系,如共享用户、共享...
广告位



