

网盘截屏
![图片[1]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11349)
案件背景
好久没更新了,继续图神经网络的应用。本次数据集是餐厅评论,主要目的是识别餐厅评论里面的欺诈者,也可以简单的说是:“水军”,数据是经典的yelp评论数据。使用的模型是GCN,GAT,GIN等图结构的神经网络。
数据介绍
该数据集由Dou等人引入,用于增强基于图神经网络的欺诈检测器,以识别伪装欺诈者。数据集包含Yelp评论,具有标签(是否欺诈)和32个归一化特征作为属性,以及评论之间的关系,如共享用户、共享餐厅评级和共享同一月份的餐厅。
数据集由Dou et al.在论文《Enhancing Graph Neural Network-based Fraud Detectors against Camouflaged Fraudsters》中引入。
数据集内容
- 顶点(Vertices): 包含Yelp评论,每个评论有标签(is_fraud)和32个归一化特征。
- 边(Edges): 描述评论间的关系,无附加属性。
- R-U-R: shares_user_with
- R-S-R: shares_restaurant_rating_with
- R-T-R: shares_restaurant_in_one_month_with
数据集文件
- net_rsr.csv
- net_rtr.csv
- net_rur.csv
- vertices.csv #节点
数据集统计信息 顶点数量: 45954 边数量:
- shares_restaurant_in_one_month_with: 1147232
- shares_restaurant_rating_with: 6805486
- shares_user_with: 98630
构建方式
yelp-frauddetection数据集由Dou等人提出,旨在通过图神经网络增强欺诈检测能力。该数据集构建于Yelp评论数据之上,通过提取评论之间的关系构建图结构。具体而言,数据集中的节点代表Yelp评论,每条评论包含32个归一化特征和一个欺诈标签(is_fraud)。边则代表评论之间的三种关系:共享用户(R-U-R)、共享餐厅评分(R-S-R)以及在同一月内共享餐厅(R-T-R)。数据预处理过程中,利用dgl库将邻接矩阵转换为边列表,并生成带有特征和标签的节点数据。
本文使用共享用户的边作为图结构的边关系。
特点
yelp-frauddetection数据集的特点在于其丰富的图结构信息和高维特征表示。数据集包含45,954个节点和8,051,348条边,其中节点特征经过归一化处理,便于模型训练。边的类型多样,涵盖了用户、餐厅评分和时间维度的关系,为欺诈检测提供了多维度的上下文信息。此外,数据集的欺诈标签为二分类任务提供了明确的监督信号,使其成为研究图神经网络在欺诈检测领域应用的理想选择。
经典使用场景
在电子商务和在线评论平台中,yelp-frauddetection数据集被广泛应用于检测虚假评论。通过分析用户评论之间的关系,如共享用户、共享餐厅评分或共享同一餐厅在一个月内的评论,该数据集能够有效识别潜在的欺诈行为。这种基于图神经网络的方法不仅提高了检测的准确性,还增强了系统对伪装欺诈者的识别能力。
yelp-frauddetection数据集在实际应用中,主要用于提升在线评论平台的信誉管理。通过实时监控和分析用户评论之间的关系,平台能够迅速识别并处理虚假评论,从而维护平台的公正性和用户的信任度。此外,该数据集还可用于优化推荐系统,确保用户获得真实可靠的推荐内容。
三方库版本
图神经网络需要使用torch深度学习框架,不知道怎么安装的可以看我之前的文章:
Anaconda安装和深度学习环境的安装(TensorFlow、Pytorch)
然后这里还需要安装torch_geometric库,用于图结构。这个包直接pip可能不太行,需要找到对应的版本。
首先要清楚自己的torch版本和cuda版本,然后安装对应的版本的torch_geometric。 例如我是torch2.3,cuda12.1,win,然后去官网看,找到对应版本的安装命令:
![图片[2]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11313)
然后安装就行了。
代码实现
还是先导入包
import os,random
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
#import networkx as nx
#import community as community_louvain
import torch
import torch.nn.functional as F
import torch_geometric
from torch import Tensor
from torch_geometric.nn import GCNConv, GATConv
from torch_geometric.data import Data
from sklearn.metrics import ( precision_score, recall_score, f1_score,
confusion_matrix, classification_report, ConfusionMatrixDisplay)
from sklearn.preprocessing import LabelEncoder
from scipy.stats import ttest_ind
print("Torch version:", torch.__version__)
print("Torch Geometric version:", torch_geometric.__version__)
![图片[3]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11314)
做一下全局设置,固定随机数种子方便复现
## 设置随机数种子
def set_seed_for_all(seed):
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed) # For single-GPU.
torch.cuda.manual_seed_all(seed) # For multi-GPU.
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(seed)
random.seed(seed)
set_seed_for_all(42)
数据概述
我们先来了解一下数据,读取,查看
elliptic_txs_features = pd.read_csv('./data/vertices.csv').drop(columns='label')
elliptic_txs_classes = pd.read_csv('./data/vertices.csv')[['node_id','label']]
elliptic_txs_edgelist = pd.read_csv('./data/net_rur.csv', header=None)
elliptic_txs_edgelist.columns = ['txId1','txId2']# + [f'V{i}' for i in range(elliptic_txs_edgelist.shape[1])] #特征名称
print(f"""形状
{4*' '}特征 : {elliptic_txs_features.shape[0]:8,} (行) {elliptic_txs_features.shape[1]:4,} (列)
{4*' '}类别 : {elliptic_txs_classes.shape[0]:8,} (行) {elliptic_txs_classes.shape[1]:4,} (列)
{4*' '}边 : {elliptic_txs_edgelist.shape[0]:8,} (行) {elliptic_txs_edgelist.shape[1]:4,} (列)
""")
![图片[4]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11315)
特征就是每个评论的X变量,33列,就是一列ID+32个特征。类别就是标签,这个评论是否属于欺诈,边就是表示这两个评论是有关系的。我们这里用的边是共享用户的边。
查看特征:
elliptic_txs_features.head(3)
![图片[5]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11316)
节点特征x,也就是每一笔交易的特征变量,这里脱敏了,用feature_n代表
elliptic_txs_classes.head(3) 节点的标签y,其实可以和上面合并的,合并了就是标准的2维表格数据。
![图片[6]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11317)
其实普通的表格数据就是上面这些,X和y就可以了,但是图数据就是会有连接,就是下面的边
elliptic_txs_edgelist.head(3) # 边的关系,表示这两笔交易有关系,这也是图数据特有的。
![图片[7]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11318)
查看一下类别分布 class.
![图片[8]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11319)
查看 比例:
elliptic_txs_classes['label'].value_counts(normalize=True).to_frame()
![图片[9]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11320)
- 85.47% 的类别是 (0) 合法
- 14.53% 的类别是 (1) 不合法
查看边和节点
num_nodes = elliptic_txs_features.shape[0]
num_edges = elliptic_txs_edgelist.shape[0]
print(f"nodes节点数量: {num_nodes:,}")
print(f"edges边的数量: {num_edges:,}")
![图片[10]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11321)
图神经网络准备
有显卡就把数据挪到GPU上算,没有就CPU算
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device![图片[11]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11322)
准备工作
边转为张量
# 创建以 txId 为键、实际索引为值的映射 #
tx_id_mapping = {tx_id: idx for idx, tx_id in enumerate(elliptic_txs_features['node_id'])} # 从节点特征中获取编号索引
edges_with_txId = elliptic_txs_edgelist[elliptic_txs_edgelist['txId1'].isin(list(tx_id_mapping.keys()))\
& elliptic_txs_edgelist['txId2'].isin(list(tx_id_mapping.keys()))] #过滤边,保留只存在于特征节点中的边
edges_with_txId['Id1'] = edges_with_txId['txId1'].map(tx_id_mapping)
edges_with_txId['Id2'] = edges_with_txId['txId2'].map(tx_id_mapping)
edges_with_txId
![图片[12]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11323)
边做个索引,方便后面构建数据。
转为torch张量
edge_index = torch.tensor(edges_with_txId[['Id1', 'Id2']].values.T, dtype=torch.long) #序号位置写到边里面去就行
edge_index
![图片[13]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11324)
节点特征张量
将特征转为张量
# 节点特征转为torch数据
node_features = torch.tensor(elliptic_txs_features.drop(columns=['node_id']).to_numpy(), dtype=torch.float)
print(node_features.shape)
node_features[:2]
![图片[14]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11325)
节点标签张量
elliptic_txs_classes['label'].value_counts()
![图片[15]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11326)
标签编码后转为torch
# 类别标签编码 Labelencode target class #
le = LabelEncoder()
class_labels = le.fit_transform(elliptic_txs_classes['label'])
original_labels = le.inverse_transform(class_labels)
node_labels = torch.tensor(class_labels, dtype=torch.long)
print(class_labels)
print(original_labels)
print(node_labels)![图片[16]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11327)
print(le.inverse_transform([0])) # licit
print(le.inverse_transform([1])) # illicit ![图片[17]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11328)
构建图神经网络数据对象
# 放入 pytorch geometric 的数据对象里面 #
data = Data(x=node_features, edge_index=edge_index, y=node_labels)
# 数据挪到 GPU 上
data = data.to(device)
## 未知的数据掩码掉
## 未知的数据掩码掉
known_mask = (data.y == 0) | (data.y == 1) # 只要已知的标签 licit or illicit
unknown_mask = data.y == 2 # 未知标签掩码
#定义训练集,验证集,测试集
num_known_nodes = known_mask.sum().item()
permutations = torch.randperm(num_known_nodes)
train_size = int(0.8 * num_known_nodes) #8成训练
val_size = int(0.1 * num_known_nodes) #1成验证
test_size = num_known_nodes - train_size - val_size #1验测试
total = np.sum([train_size, val_size, test_size])
print(f"""Number of observations per split
Training : {train_size:10,} ({100*train_size/total:0.2f} %)
Validation : {val_size:10,} ({100*val_size/total:0.2f} %)
Testing : {test_size:10,} ({100*test_size/total:0.2f} %)
""")
![图片[18]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11329)
给训练集,验证集,测试集作一些掩码,后面训练模型要用
#为 Train、Val、Test 的索引创建掩码
data.train_mask = torch.zeros(data.num_nodes, dtype=torch.bool)
data.val_mask = torch.zeros(data.num_nodes, dtype=torch.bool)
data.test_mask = torch.zeros(data.num_nodes, dtype=torch.bool)
train_indices = known_mask.nonzero(as_tuple=True)[0][permutations[:train_size]] #返回非0元素索引(已知节点索引), 前80%训练
val_indices = known_mask.nonzero(as_tuple=True)[0][permutations[train_size:train_size + val_size]] #80%-90验证
test_indices = known_mask.nonzero(as_tuple=True)[0][permutations[train_size + val_size:]] #90%-100测试
data.train_mask[train_indices] = True
data.val_mask[val_indices] = True
data.test_mask[test_indices] = True
train_indices.shape ,data.train_mask.shape, data.train_mask.cpu().numpy().shape
![图片[19]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11330)
训练集,验证集,测试集 标记一下,转为数据框,备用存储, 后续去用于其他模型建模。
df_elliptic_txs_all=elliptic_txs_features.merge(elliptic_txs_classes,how='left',right_on='node_id', left_on='node_id' )
# 假设你的原始数据框是 df,包含所有节点
# 首先创建一个新列,默认值为 'unused' 或其他标记
df_elliptic_txs_all['split'] = 'unused' # 或其他默认值
# 将掩码转换为 numpy 数组(确保在 CPU 上)
train_mask_np = data.train_mask.cpu().numpy()
val_mask_np = data.val_mask.cpu().numpy()
test_mask_np = data.test_mask.cpu().numpy()
# 根据掩码设置 split 列的值
df_elliptic_txs_all.loc[train_mask_np, 'split'] = 'train'
df_elliptic_txs_all.loc[val_mask_np, 'split'] = 'val'
df_elliptic_txs_all.loc[test_mask_np, 'split'] = 'test'
df_elliptic_txs_all['label'] = data.y.cpu().numpy()
df_elliptic_txs_all.shape
存储:
df_elliptic_txs_all.to_csv('data_split.csv',index=False)
存下来的数据我后续会使用标准的其他机器学习方法来对比,到底是图神经网络效果好还是其他普通的例如神经网络,xgboost这种树模型标果好。
统计一下数据集里面的训练集,验证集,测试集的黑白样本比例。
# 数据集比例统计 #
sets = ['train', 'val', 'test'] ; rows = []
for split in sets:
mask = getattr(data, f'{split}_mask')
licit = (data.y[mask] == 1).sum().item()
illicit = (data.y[mask] == 0).sum().item()
total = licit + illicit
rows.append([ split, total,
licit, round(licit/total*100, 2),
illicit, round(illicit/total*100, 2) ])
pd.DataFrame(rows, columns=['Set', 'Total', 'Licit', 'Licit (%)', 'Illicit', 'Illicit (%)'] )
![图片[20]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11331)
每个数据集里面的黑白占比类似,PSI稳定,正好。
训练函数餐厅评论
### 三种图神经网络,存储中间的一些结果
# 验证集指标字典
val_metrics_gnns = {
'gcn': {
'precisions': [],
'probas': []
},
'gat': {
'precisions': [],
'probas': []
},
'gin': {
'precisions': [],
'probas': []
}
}
# 测试集预测概率字典
test_predict_prob_gnns = {
'gcn': {
'licit': {'probas': []},
'illicit': {'probas': []}
},
'gat': {
'licit': {'probas': []},
'illicit': {'probas': []}
},
'gin': {
'licit': {'probas': []},
'illicit': {'probas': []}
}
}
# 训练,预测,评估函数
def compute_metrics(y_true, y_pred):
"""计算并返回准确率、精度、召回率和F1分数"""
accuracy = (y_true == y_pred).mean()
precision = precision_score(y_true, y_pred, average='weighted', zero_division=0)
recall = recall_score(y_true, y_pred, average='weighted', zero_division=0)
f1 = f1_score(y_true, y_pred, average='weighted', zero_division=0)
return accuracy, precision, recall, f1
def evaluate(model, data, mask):
model.eval()
with torch.no_grad():
y_pred = model(data).argmax(dim=1)
y_true, y_pred = data.y[mask].cpu().numpy(), y_pred[mask].cpu().numpy()
return dict( zip( ['accuracy', 'precision', 'recall', 'f1_score'], compute_metrics(y_true, y_pred) ) )
def predict(model, data):
model.eval()
with torch.no_grad():
out = model(data)
pred = out.argmax(dim=1)
return pred
def predict_probabilities(model, data):
model.eval()
with torch.no_grad():
out = model(data)
probabilities = torch.exp(out)
return probabilities
训练函数,具体做什么里面都有备注。
def train_gnn(num_epochs, data, model, optimizer, criterion):
metrics = {
'train': {'losses': [], 'accuracys': [], 'precisions': [], 'recalls': [], 'f1_scores': []},
'val': {'accuracys': [], 'precisions': [], 'recalls': [], 'f1_scores': []} }
for epoch in range(1, num_epochs + 1):
# 训练部分
model.train()
optimizer.zero_grad()
out = model(data)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step() #更新参数
# 训练集评估
train_metrics = evaluate(model, data, data.train_mask)
metrics['train']['losses'].append(loss.item())
for metric in ['accuracy', 'precision', 'recall', 'f1_score']:
metrics['train'][f'{metric}s'].append(train_metrics[metric])
# 验证集评估
val_metrics = evaluate(model, data, data.val_mask)
for metric in ['accuracy', 'precision', 'recall', 'f1_score']:
metrics['val'][f'{metric}s'].append(val_metrics[metric])
# 日志打印
if epoch % 10 == 0:
print(f'Epoch {epoch:03d}, Loss: {loss:.4f}, '
f'Train - Acc: {train_metrics["accuracy"]:.4f} - Prec: {train_metrics["precision"]:.4f} - '
f'Rec: {train_metrics["recall"]:.4f} - F1: {train_metrics["f1_score"]:.4f}')
print(f' Val - Acc: {val_metrics["accuracy"]:.4f} - '
f'Prec: {val_metrics["precision"]:.4f} - Rec: {val_metrics["recall"]:.4f} - '
f'F1: {val_metrics["f1_score"]:.4f}')
return metrics
画图用的函数
def plot_metric_subplot(subplot_position, x_range, train_metric, val_metric, test_metric, metric_name):
plt.subplot(2, 2, subplot_position)
plt.plot(x_range, train_metric, color='C0', linewidth=1.0, label='Training')
plt.plot(x_range, val_metric, color='C1', linewidth=1.0, label='Validation', linestyle=':')
plt.axhline(y=test_metric, color='C2', linewidth=0.5, linestyle='--', label='Test')
plt.xlabel('Epoch')
plt.ylabel(metric_name)
plt.legend(fontsize=8)
plt.title(metric_name)
def plot_train_val_test_metrics(train_val_metrics, test_metrics, num_epochs):
plt.figure(figsize=(8, 5),dpi=128)
x_range = range(1, num_epochs + 1)
metrics = [('accuracys', 'Accuracy'),('precisions', 'Precision'), ('recalls', 'Recall'), ('f1_scores', 'F1-Score') ]
for i, (metric_key, metric_name) in enumerate(metrics, start=1):
plot_metric_subplot( i, x_range,
train_val_metrics['train'][metric_key], train_val_metrics['val'][metric_key],
test_metrics[metric_key[:-1]], # Remove the trailing 's' for test metric key
metric_name )
plt.tight_layout()
plt.show()
GCN网络
![图片[21]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11332)
开始第一个图神经网络
定义GCN
# GCN类的定义
class GCN(torch.nn.Module):
def __init__(self, num_node_features, num_classes):
super(GCN, self).__init__()
self.conv1 = GCNConv(num_node_features, 16)
self.conv2 = GCNConv(16, num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
# 初始化
model = GCN(num_node_features=data.num_features, num_classes=len(le.classes_)).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=0.0005)
criterion = torch.nn.CrossEntropyLoss() # 多分类
data = data.to(device) #数据移到cuda上
训练100轮
#训练
NUM_EPOCHS = 100
train_val_metrics = train_gnn(NUM_EPOCHS, data, model, optimizer, criterion)
val_metrics_gnns['gcn']['precisions'] = train_val_metrics['val']['precisions']![图片[22]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11333)
评估,计算测试集上的评估指标
model.eval()
with torch.no_grad():
t_m = evaluate(model, data, data.test_mask)
print(f" Test - Acc: {t_m['accuracy']:.4f} Prec: {t_m['precision']:.4f} Rec: {t_m['recall']:.4f} F1: {t_m['f1_score']:.4f}")
![图片[23]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11334)
plot_train_val_test_metrics(train_val_metrics, t_m, NUM_EPOCHS)![图片[24]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11335)
可以看到100轮后基本收敛。测试集的F1值0.85左右
测试集的预测概率存储一下
# 获取概率
probas = predict_probabilities(model, data) # 返回的是 [num_nodes, num_classes] 的张量
train_probas = probas[data.train_mask].cpu().numpy()
test_probas = probas[data.test_mask].cpu().numpy()
# 存储概率结果
test_predict_prob_gnns['gcn']['licit']['probas'] = test_probas[:, 0]
test_predict_prob_gnns['gcn']['illicit']['probas'] = test_probas[:, 1]
GAT网络
![图片[25]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11336)
定义网络
# 定义 GAT #
class GAT(torch.nn.Module):
def __init__(self, num_node_features, num_classes, num_heads=8):
super(GAT, self).__init__()
self.conv1 = GATConv(num_node_features, 8, heads=num_heads, dropout=0.2)
self.conv2 = GATConv(8 * num_heads, num_classes, heads=1, concat=False, dropout=0.2)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.elu(x)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
model = GAT(num_node_features=data.num_features, num_classes=len(le.classes_)).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=0.0005)
criterion = torch.nn.CrossEntropyLoss() # Since we have a multiclass classification problem.
data = data.to(device)
训练
# Train #
train_val_metrics = train_gnn(NUM_EPOCHS, data, model, optimizer, criterion)
val_metrics_gnns['gat']['precisions'] = train_val_metrics['val']['precisions']
.
![图片[26]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11337)
打印测试集评估指标
# 评估并打印测试集指标
model.eval()
with torch.no_grad():
t_m = evaluate(model, data, data.test_mask)
print(f" Test - Acc: {t_m['accuracy']:.4f} Prec: {t_m['precision']:.4f} Rec: {t_m['recall']:.4f} F1: {t_m['f1_score']:.4f}")
![图片[27]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11338)
画图
plot_train_val_test_metrics(train_val_metrics, t_m, NUM_EPOCHS)
![图片[28]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11339)
存储一下预测的概率
probas = predict_probabilities(model, data) # 返回的是 [num_nodes, num_classes] 的张量
train_probas = probas[data.train_mask].cpu().numpy()
test_probas = probas[data.test_mask].cpu().numpy()
# 存储概率结果
test_predict_prob_gnns['gat']['licit']['probas'] = test_probas[:, 0]
test_predict_prob_gnns['gat']['illicit']['probas'] = test_probas[:, 1]
GIN网络
![图片[29]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11340)
定义模型
# 定义 GIN #
from torch_geometric.nn import GINConv, global_add_pool
import torch.nn.functional as F
class GIN(torch.nn.Module):
def __init__(self, num_node_features, num_classes):
super(GIN, self).__init__()
# 1st GIN layer.
nn1 = torch.nn.Sequential(
torch.nn.Linear(num_node_features, 32),
torch.nn.ReLU(),
torch.nn.Linear(32, 32)
)
self.conv1 = GINConv(nn1)
# 2nd GIN layer.
nn2 = torch.nn.Sequential(
torch.nn.Linear(32, 32),
torch.nn.ReLU(),
torch.nn.Linear(32, 32)
)
self.conv2 = GINConv(nn2)
self.fc = torch.nn.Linear(32, num_classes)
def forward(self, data):
x, edge_index, batch = data.x, data.edge_index, data.batch
x = self.conv1(x, edge_index)
x = F.relu(x)
x = self.conv2(x, edge_index)
# x = global_add_pool(x, batch)
x = self.fc(x)
return F.log_softmax(x, dim=1)
# 初始化 #
model = GIN(num_node_features=data.num_features, num_classes=len(le.classes_)).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=0.0005)
criterion = torch.nn.CrossEntropyLoss()
data = data.to(device)
训练数据:
# 训练 #
train_val_metrics = train_gnn(NUM_EPOCHS, data, model, optimizer, criterion)
val_metrics_gnns['gin']['precisions'] = train_val_metrics['val']['precisions']
![图片[30]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11341)
评估
# 评估,计算测试集上的评估指标
model.eval()
with torch.no_grad():
t_m = evaluate(model, data, data.test_mask)
print(f" Test - Acc: {t_m['accuracy']:.4f} Prec: {t_m['precision']:.4f} Rec: {t_m['recall']:.4f} F1: {t_m['f1_score']:.4f}")
画图
plot_train_val_test_metrics(train_val_metrics, t_m, NUM_EPOCHS)
![图片[31]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11343)
未出现过拟合情况
存储预测的概率
# 获取概率
probas = predict_probabilities(model, data) # 返回的是 [num_nodes, num_classes] 的张量
train_probas = probas[data.train_mask].cpu().numpy()
test_probas = probas[data.test_mask].cpu().numpy()
# 存储概率结果
test_predict_prob_gnns['gin']['licit']['probas'] = test_probas[:, 0]
test_predict_prob_gnns['gin']['illicit']['probas'] = test_probas[:, 1]
GNN们对比
plt.figure(figsize=(8, 4),dpi=128)
epochs = range(1, len(val_metrics_gnns['gcn']['precisions']) + 1)
plt.plot(epochs, val_metrics_gnns['gcn']['precisions'], color='C0', linewidth=1.2, linestyle='--', label='GCN')
plt.plot(epochs, val_metrics_gnns['gat']['precisions'], color='C1', linewidth=1.2, linestyle='-.', label='GAT')
plt.plot(epochs, val_metrics_gnns['gin']['precisions'], color='C2', linewidth=1.2, linestyle=':', label='GIN')
plt.xlabel('Epoch')
plt.ylabel('Precision')
plt.title('Validation Precisions Comparison Across GNN Models')
plt.legend(fontsize=10)
plt.grid(False)
plt.tight_layout()
plt.show()
就精度而言,GIN 的总体表现似乎最好,尤其是在后期稳定之后。它的精度最高,但初期表现出不稳定性。
![图片[32]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11344)
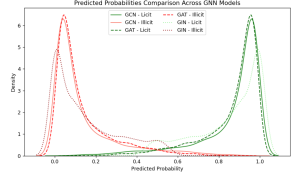
画出预测的概率密度图
ALPHA = 0.9 ; FILL = False
plt.figure(figsize=(8, 5), dpi=128)
# 定义模型参数:模型名、合法类颜色、非法类颜色、线型
model_params = [ ('gcn', 'forestgreen', 'salmon', '-'), ('gat', 'darkgreen', 'red', '--'), ('gin', 'lightgreen', 'darkred', ':')]
# 绘制所有曲线
for model, licit_color, illicit_color, linestyle in model_params:
# 合法类
sns.kdeplot(test_predict_prob_gnns[model]['licit']['probas'], fill=FILL, color=licit_color, linestyle=linestyle,
alpha=ALPHA, label=f"{model.upper()} - Licit")
# 非法类
sns.kdeplot(test_predict_prob_gnns[model]['illicit']['probas'], fill=FILL, color=illicit_color, linestyle=linestyle,
alpha=ALPHA, label=f"{model.upper()} - Illicit")
plt.title("Predicted Probabilities Comparison Across GNN Models")
plt.xlabel("Predicted Probability")
plt.ylabel("Density")
plt.legend(loc="upper center", ncol=2)
plt.tight_layout()
plt.show()
![图片[33]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11345)
箱线图
# 准备箱线图数据
box_data = pd.DataFrame(
[(model_name.upper(), category.capitalize(), proba)
for model_name in ['gcn', 'gat', 'gin']
for category in ['licit', 'illicit']
for proba in test_predict_prob_gnns[model_name][category]['probas']],
columns=['Model', 'Class', 'Probability']
)
# 创建绘图
plt.figure(figsize=(8, 4), dpi=128)
sns.boxplot(y='Model', x='Probability', hue='Class', data=box_data,
linewidth=2.5, fliersize=0.5, palette={'Licit': 'forestgreen', 'Illicit': 'indianred'},
flierprops={ 'marker': 'o', 'markersize':5, 'markerfacecolor': 'None', 'markeredgecolor': 'C0', 'alpha': 0.2 }
)
# 美化图形
plt.grid(True, axis='x', color='lightgrey', linestyle='-', linewidth=0.5)
plt.title("Comparison of Predicted Probabilities Across GNN's")
plt.xlabel("Predicted Probability")
plt.ylabel("GNN Model")
plt.legend(loc="center left", bbox_to_anchor=(1, 0.5))
plt.tight_layout()
plt.show()
![图片[34]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11346)
评价指标
数据挪回CPU
y_test=data.y[data.test_mask].cpu().numpy()
y_test.shape
y_test=pd.Series(y_test)
y_test.value_counts()![图片[35]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11347)
predictions={'gcn':test_predict_prob_gnns['gcn']['illicit']['probas'],
'gat':test_predict_prob_gnns['gat']['illicit']['probas'],
'gin':test_predict_prob_gnns['gin']['illicit']['probas']}
predictions.keys()定义评价指标函数
from sklearn.metrics import confusion_matrix,roc_curve, auc
from sklearn.metrics import classification_report
from sklearn.metrics import cohen_kappa_score
def evaluation(y_test, y_proba,te=0.2):
y_predict=(y_proba>te)*1
fpr, tpr, _ = roc_curve(y_test, y_proba)
roc_auc = auc(fpr, tpr) # 计算 AUC
accuracy=classification_report(y_test, y_predict,output_dict=True)['accuracy']
s=classification_report(y_test, y_predict,output_dict=True)['weighted avg']
precision=s['precision']
recall=s['recall']
f1_score=s['f1-score']
#kappa=cohen_kappa_score(y_test, y_predict)
return accuracy,precision,recall,f1_score,roc_auc #, kappa
查看不同的GNN的评价指标
df_eval=pd.DataFrame(columns=['Accuracy','Precision','Recall','F1_score','AUC'])
for name, y_proba in predictions.items():
s=evaluation(y_test.to_numpy(),y_proba)
df_eval.loc[name,:]=list(s)
df_eval
![图片[36]-【Python数据分析案例(2025)】21——基于图神经网络的餐厅评论反欺诈识别](http://img.seekresource.com/img/11348)
在欺诈识别这个二分类任务中,三种神经网络模型各有特点。GCN模型的准确率、召回率和 F1 分数分别为 0.835509、0.835509、0.847082,在这三个指标上表现均衡且整体较优,能较好地识别欺诈情况,同时其 AUC 达到 0.857013,综合考虑各类阈值下的性能较好。GAT 模型准确率稍低,为 0.828764,但精确率 0.863057 与 GCN 相近,其 AUC 为 0.85861,与 GCN 也较为接近,整体表现稍逊于 GCN。GIN 模型准确率、召回率和 F1 分数分别为 0.780244、0.780244、0.80619,在这三个指标上表现相对较弱,不过其精确率 0.864403 是三个模型中最高的,说明在预测为欺诈的样本中,正确欺诈的比例较高,但可能漏掉不少欺诈样本,其 AUC 为 0.858433,与 GCN 和 GAT 相比也偏低。综合来看,GCN 模型在这次欺诈识别任务中整体性能最佳,GAT 次之,GIN 则在某些特定方面有优势,但整体稍差。
下一篇我会使用同样的数据,同样的训练集和测试集进行普通机器学习的模型训练和预测,看看是图神经网络效果好还是普通的树模型效果好。
创作不易,看官觉得写得还不错的话点个关注和赞吧,我们会持续更新python数据分析领域的代码文章~
看完不过瘾,那就自己发一篇吧!








![表情[nanguo]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/nanguo.gif)
![表情[haobang]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/haobang.gif)
![表情[shuai]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/shuai.gif)
![表情[deyi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/deyi.gif)
![表情[chi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/chi.gif)



暂无评论内容