
在 AI 圈疯狂内卷的当下,DeepSeek 于 10 月 20 日祭出的 DeepSeek-OCR,终于让我们看到了真正的技术革新。这个被命名为 “OCR” 的模型,实则开启了 AI 处理信息的全新维度 ——它既是文档解析的全能扫描仪,更是破解大模型长上下文困局的「光学压缩器」。正如 DeepSeek-R1 在 LLM 领域掀起的波澜,这次的 DeepSeek-OCR 同样将重塑行业认知。
一、传统 OCR 的「破壁者」:从文本搬运工到智能重构师
传统 OCR 只能机械地将图片文字转化为 TXT,而 DeepSeek-OCR 的表现堪称 「文档级 AI 解构专家」:
- 结构化输出能力
![图片[1]-Python自动化:DeepSeek-OCR,重新定义OCR,让AI“看见”更高效,重新定义 AI「视觉 – 语言」交互范式-寻找资源网](http://img.seekresource.com/img/13213)
- 多模态解析边界突破
二、破解大模型「失忆症」:革命性的「上下文光学压缩」
当前所有大模型都面临 「Token 爆炸」难题 :处理百万 Token 级文本时,计算量随长度平方增长,导致成本飙升且效率暴跌。
![图片[3]-Python自动化:DeepSeek-OCR,重新定义OCR,让AI“看见”更高效,重新定义 AI「视觉 – 语言」交互范式-寻找资源网](http://img.seekresource.com/img/13214)
DeepSeek-OCR 另辟蹊径,提出了 「用视觉压缩替代文本处理」的颠覆性方案:
- 压缩即智能的核心逻辑
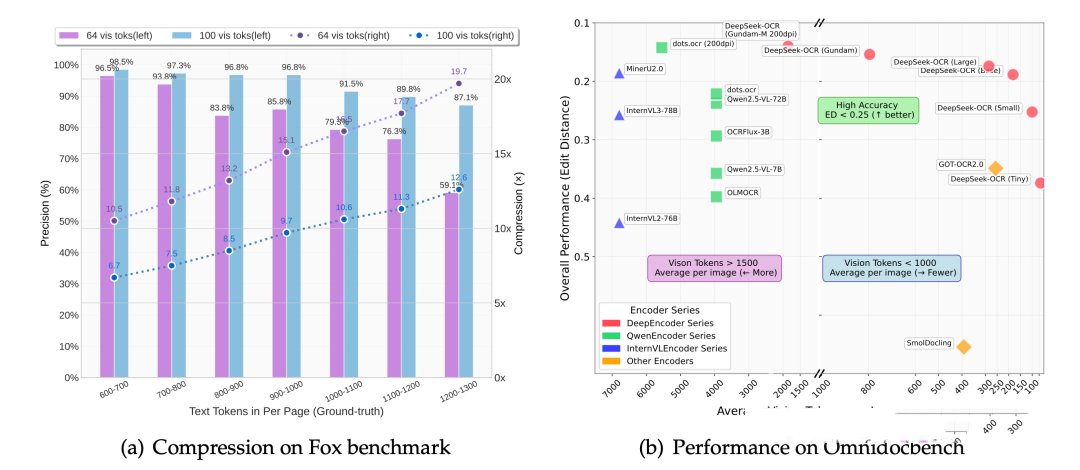
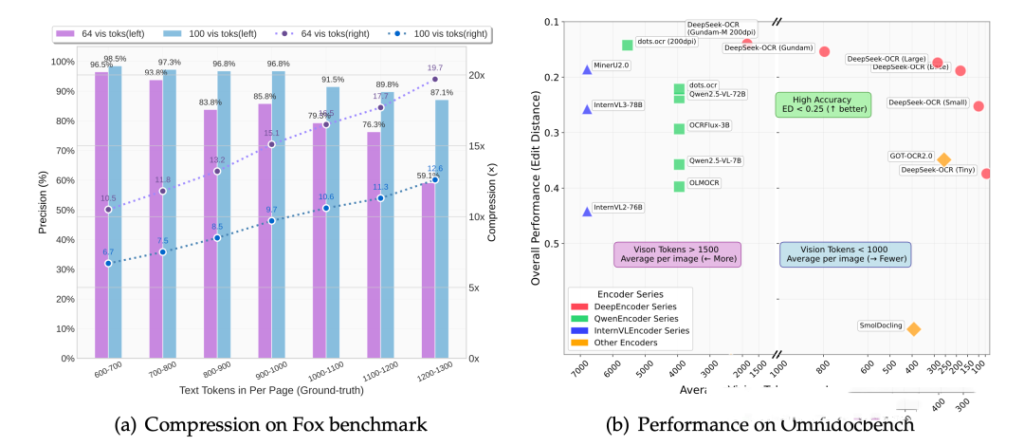
将长文本渲染为图像,通过 DeepEncoder 压缩成原 Token 数量 1/10 的视觉 Token(压缩比 10x 时精度 97%),再由 MoE 解码器还原。这就像把一维的「文字薯条」转化为二维的「信息大饼」,让模型能「一眼扫尽全局」,让信息由原来只有前后信息的一维维度升级为具有前后左右的二维维度,一维的文字,就像一根无限长的薯条,你想吃它,智能从头吃到尾,一个字节都不能少。而二维的图像,就像一张大饼,你一眼扫过去,整个饼的全貌,尽收眼底。DeepSeek-OCR,干的就是这事,把所有的文字,全部压缩成图像。 - 动态遗忘机制的仿生学突破
模拟人类记忆衰退曲线,对久远上下文逐步缩小图像分辨率(从 Gundam 到 Tiny 模式),实现 Token 消耗的指数级递减。例如, 假设你正在跟一个AI助手聊天,你俩已经聊了很长时间,聊了 1000轮,可能占几十万甚至几百万的Token。目前的大语言模型通常会返回如下信息
![图片[4]-Python自动化:DeepSeek-OCR,重新定义OCR,让AI“看见”更高效,重新定义 AI「视觉 – 语言」交互范式-寻找资源网](http://img.seekresource.com/img/13215)
或者对于目前的大模型来说,当你问:“哎,我跟你说的第一件事是啥?”,大模型就必须把这1000轮的全部聊天记录都装进它的记忆区也就是上下文窗口里,才能去查找。这会撑爆它的内存和算力,所以现在的AI,很多的聊着聊着你就感觉它失忆,因为有的,真的只能记住最近的几十轮对话。
而DeepSeek-OCR的解决方案呢,是这样的。
AI助手只把最近10轮的聊天记录,用文本的形式记在脑子里。
但是,它把那更远一点的990轮的文本聊天记录,自动渲染成一张或着几张长长的图片,就像你给聊天记录截了个屏。
然后,它立刻调用内部的DeepEncoder编码器,把这张包含海量文字的截图,压缩成大概只有原来10分之1的视觉Token,然后一起扔到上下文中,记到脑子里。
当真正要用的时候,比如你还是问那个问题,“我说的第一件事是啥?”
它现在的上下文里装的是10轮聊天记录的文本token + 990轮聊天记录的视觉token。
然后,它的解码器,DeepSeek-3B,一个激活参数为570M的MOE模型,已经通过 OCR 任务,学会了一看到这种视觉token,就能把它解码还原成原文的能力。
于是,他看了一眼那一圈视觉Token,找到了第一句话,然后回答了你
这种技术突破带来的直接价值是:
- 成本革命
单块 A100-40G GPU 每天可处理 20 万页文档,生成大模型训练数据的效率提升 10 倍。 - 体验颠覆
AI 助手终于能「记住」三十天前的对话细节,而无需消耗海量显存。
三、架构解析:从「像素感知」到「语义理解」的全链路创新
DeepSeek-OCR 的强大源于其 「感知 – 压缩 – 理解 – 生成」的四阶架构 :
- SAM 感知层
像侦察兵般快速定位文档关键区域,支持 512×512 到 1280×1280 的多分辨率输入。快速定位出文档或者图片中最重要最核心的内容,比如还是之前1000轮聊天的案例,前990轮聊天保存为图片类型,通过SAM提取出最核心最重要的内容从而实现token压缩。 - 信息压缩器
通过卷积神经网络将 4096 个 Patch Token 压缩至 256 个,实现「像素级冗余消除」去除冗余,只保留最精华的部分,生成极少量的“视觉 token”。比如将之前990轮对话的截图压缩为几百个Token。 - CLIP 理解层
全局语义关联,将零散视觉特征整合为结构化知识,如同情报分析师提炼关键信息整合成一份完整的摘要信息。 -
MoE 解码器
![图片[5]-Python自动化:DeepSeek-OCR,重新定义OCR,让AI“看见”更高效,重新定义 AI「视觉 – 语言」交互范式-寻找资源网](http://img.seekresource.com/img/13216)
![图片[6]-Python自动化:DeepSeek-OCR,重新定义OCR,让AI“看见”更高效,重新定义 AI「视觉 – 语言」交互范式-寻找资源网](http://img.seekresource.com/img/13217)
这种分工明确的架构,让模型在保持高分辨率细节感知的同时,将计算复杂度从 O (N²) 降至 O (1),真正实现了「用最少的 Token 传递最多的信息」。
四、开发者福音:开箱即用的多模态「超级引擎」
DeepSeek-OCR 的开源生态为行业带来了前所未有的便利:
- 安装环境
CUDA: 11.8
PyTorch: 2.6.0
Python: 3.12.9安装步骤
1. 克隆仓库
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
cd DeepSeek-OCR2.创建并激活 Conda 环境
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr3. 安装依赖包
下载vllm-0.8.5:https://github.com/vllm-project/vllm/releases/tag/v0.8.5
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation调用代码
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
# prompt = "<image>\nFree OCR. "
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'your_image.jpg'
output_path = 'your/output/dir'
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)五、技术哲学:回归人类本能的「数字进化」
DeepSeek-OCR 的突破性不仅在于技术指标,更在于其 「向生物学习」的底层逻辑 :
- 视觉优先的认知革命
人类祖先用了数百万年进化出视觉主导的信息处理系统,而 DeepSeek-OCR 证明,二维视觉压缩比一维文本处理更适合 AI 的「大脑」。 - 遗忘机制的主动设计
通过动态调整压缩率模拟记忆衰退,让模型学会「选择性遗忘」,这与《西部世界》中「错误是进化的工具」的哲学不谋而合。
这种「仿生学 AI」的探索,或许正在开启「数字生命」的新维度 —— 当 AI 开始像人类一样「看」世界、「记」重点、「忘」细节,我们离真正的通用智能又近了一步。
结语:一场静默的「信息革命」
DeepSeek-OCR 的出现,标志着 AI 处理信息的范式正在从「文本搬运」转向「语义蒸馏」。它不仅是 OCR 技术的里程碑,更是大模型时代「降本增效」的关键钥匙。对于开发者而言,这是一个可以立即落地的「超级工具」;对于行业而言,这是多模态应用爆发的导火索。
现在,点击下方链接获取 DeepSeek-OCR 的完整代码和论文,亲自体验这场「光学压缩」带来的震撼:
- GitHub 项目:
- Hugging Face 模型:
在这个信息过载的时代,DeepSeek-OCR 教会我们:真正的智能,从来不是事无巨细的记录,而是精准的压缩与优雅的遗忘。







![表情[nanguo]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/nanguo.gif)
![表情[haobang]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/haobang.gif)
![表情[shuai]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/shuai.gif)
![表情[deyi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/deyi.gif)
![表情[chi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/chi.gif)



暂无评论内容