
项目介绍
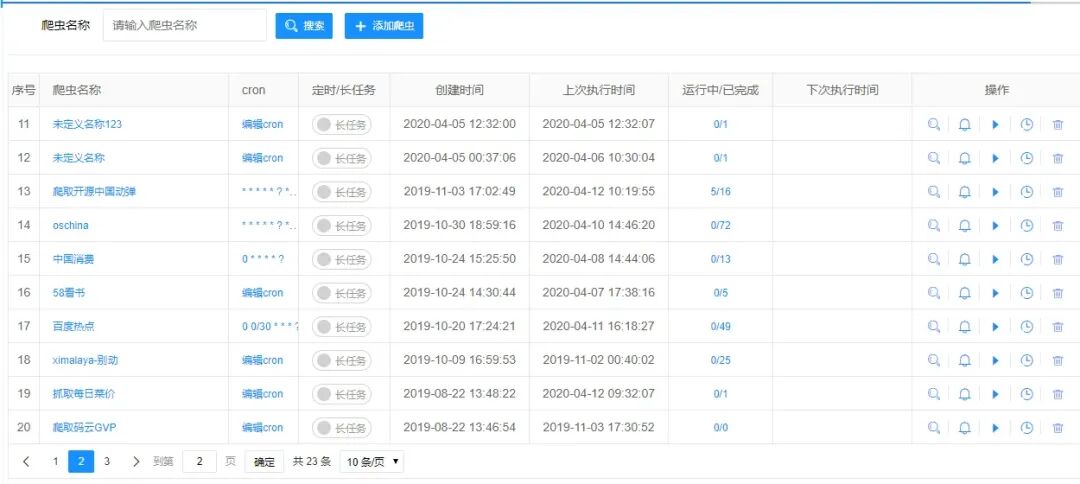
Spider-Flow 是一款以图形化方式定义爬虫流程的开源爬虫平台,用户无需编写代码即可完成爬虫任务,极大地降低了爬虫开发的门槛,提高了开发效率。
应用场景
-
数据采集: 适用于需要从网页上采集大量结构化或非结构化数据的场景,如商品信息、新闻资讯、社交媒体数据等。 -
市场调研: 通过采集竞争对手或行业相关的数据,进行市场分析和竞品研究。 -
内容聚合: 将多个网站或页面的内容进行聚合,形成统一的信息源,便于用户浏览和检索。 -
自动化测试: 在Web应用测试中,模拟用户操作进行数据抓取和验证,提高测试效率和准确性。
功能模块
-
图形化界面: 提供直观的图形化界面,用户可以通过拖拽组件的方式定义爬虫流程。 -
组件库: 包含丰富的爬虫组件,如HTTP请求、数据解析、数据存储等,满足各种爬虫需求。 -
流程调度: 支持爬虫流程的定时调度和触发执行,实现自动化爬取。 -
数据存储: 支持将爬取的数据存储到多种数据库中,如MySQL、MongoDB等。 -
日志管理: 提供详细的日志记录功能,便于用户监控爬虫运行状态和排查问题。
功能特点
-
零代码开发: 用户无需编写代码,通过图形化界面即可完成爬虫任务的定义和配置。 -
高效灵活: 采用组件化设计,用户可以根据需求自由组合和配置组件,实现高效灵活的爬虫开发。 -
可扩展性强: 支持自定义组件的开发和集成,满足用户特定的爬虫需求。 -
易于维护: 图形化界面使得爬虫流程一目了然,便于用户进行维护和更新。
项目技术栈
-
前端技术: 可能采用HTML5、CSS3、JavaScript等前端技术构建图形化界面,提供良好的用户体验。(具体前端框架未在项目介绍中明确提及,但通常这类项目会使用Vue、React等流行框架) -
后端技术: 后端服务可能采用Java、Python等语言开发,提供RESTful API与前端进行交互。(具体后端技术栈未在项目介绍中明确提及,但Java Spring Boot、Python Flask/Django等是常见选择) -
数据库技术: 支持多种数据库存储爬取的数据,如MySQL、MongoDB等,满足不同场景下的数据存储需求。 -
爬虫技术: 底层可能采用成熟的爬虫框架或库,如Scrapy(Python)、Jsoup(Java)等,实现高效的数据抓取和解析。 -
调度与监控: 可能采用Quartz等调度框架实现爬虫流程的定时调度,同时集成日志框架如Log4j、SLF4J等进行日志管理。
功能演示
![图片[2]-一款开源、免费的爬虫平台,以图形化方式定义爬虫流程,不写代码即可完成爬虫!-寻找资源网](http://img.seekresource.com/img/13698)
![图片[3]-一款开源、免费的爬虫平台,以图形化方式定义爬虫流程,不写代码即可完成爬虫!-寻找资源网](http://img.seekresource.com/img/13699)
![图片[4]-一款开源、免费的爬虫平台,以图形化方式定义爬虫流程,不写代码即可完成爬虫!-寻找资源网](http://img.seekresource.com/img/13700)
![图片[5]-一款开源、免费的爬虫平台,以图形化方式定义爬虫流程,不写代码即可完成爬虫!-寻找资源网](http://img.seekresource.com/img/13701)
![图片[6]-一款开源、免费的爬虫平台,以图形化方式定义爬虫流程,不写代码即可完成爬虫!-寻找资源网](http://img.seekresource.com/img/13702)
开源地址
看完不过瘾,那就自己发一篇吧!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END







![表情[nanguo]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/nanguo.gif)
![表情[haobang]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/haobang.gif)
![表情[shuai]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/shuai.gif)
![表情[deyi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/deyi.gif)
![表情[chi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/chi.gif)



暂无评论内容