
![图片[1]-Python高效办公:告别手动录入!这个发票批量自动汇总方法太牛了,财务人紧急收藏!(附代码)-寻找资源网](http://img.seekresource.com/img/12514)
![图片[2]-Python高效办公:告别手动录入!这个发票批量自动汇总方法太牛了,财务人紧急收藏!(附代码)-寻找资源网](http://img.seekresource.com/img/12515)
如果只是一些少量的发票,手动复制粘贴和录入就能完成。每张发票1-2分钟,仔细核对也不在话下。如果要汇总海量的发票,其煎熬程度可想而知。更为崩溃的是,万一电脑突然卡死或者失误操作,前面的工作全都白干……
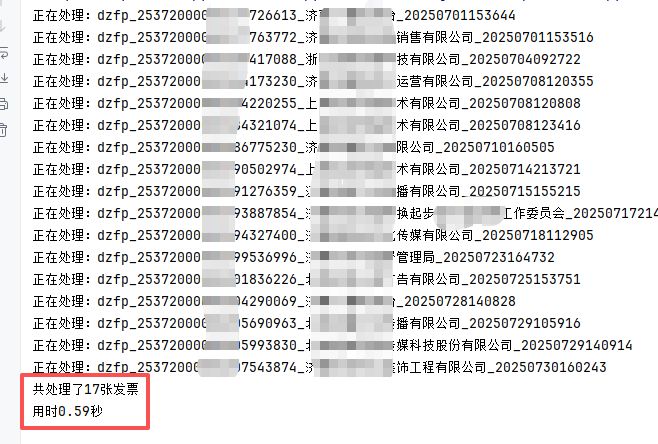
一键运行,秒级结果就在眼前:
![图片[4]-Python高效办公:告别手动录入!这个发票批量自动汇总方法太牛了,财务人紧急收藏!(附代码)-寻找资源网](http://img.seekresource.com/img/12517)
很多朋友看到代码会觉得 “复杂”,其实只要拆解开,每部分都很简单。
第一步、导入所需模块
import pdfplumber
from pathlib import Path
import re
import pandas as pd
import timepdfplumber:专门读取PDF的库,可使用pip install pdfplumber命令安装。pandas:处理表格数据的神器,最后用它生成Excel,可使用pip install pandas命令安装。pathlib:主要作用是处理文件路径。import re:导入正则表达式import time:时间戳,用于记录开始时间和结束时间。
第二步、设置提取信息的函数
汇总发票的本质就是从文件中找出指定格式的文字,再把关键部分提取出来。完成此项工作主要依靠正则表达式。通过设置相应的函数,把文本放入到下面表达式,最终返回想要的结果。
1、date_kaipiao(text):提取开票日期的函数
def date_kaipiao(text):
if m := re.search(r"开票日期:([\d]{4}年[\d]{1,2}月[\d]{1,2}日)",text):
return m.group(1)
else:
return None-
re.search:作用是搜索整个字符串然后第一个匹配到指定的字符则返回值 -
r”开票日期:([\d]{4}年[\d]{1,2}月[\d]{1,2}日)”:正则表达式,意思是从text中找包含“开票信息:”的字符串,后面为4位数据+年+(1-2位数字)+月+(1-2位数字)+日。 -
m.group(1):把正则表达式括号里的内容提取出来,去掉前面的“开票日期:” -
如果没有找到符合条件的内容,就返回None,避免出错。
2、其他函数:
-
leixing():通过关键词判断发票类型,含”增值税”即为专用发票,不含的为普通发票。 -
haoma_fapiao():提取10-20位的数字发票号。 -
name_gongsi():捕获”名称:”后的中文企业名,[一-龢]匹配所有中文字符。 -
feiyong():提取经济活动的主要内容。 -
jia_shui():处理价税分离数据,以元组形式返回金额和税额。 -
chaolianjie():生成可点击跳转的Excel超链接,方便打开文件溯源核查。file.absolute()用于获取文件的完整路径。file.stem用于获取文件不带后缀名的主名。 每个人的发票格式可能不一样,如“合计”、“总计”,只需修改对应的正则表达式即可。
第三步、变量初始化
s_t = time.time()
path = Path(r"E:\例子\pdf发票汇总")
dic = {key: [] for key in ["开票日期", "票据类型", "公司名称", "费用名称", "金额","税额", "价税合计", "发票编号", "领票人", "其他", "文件路径"]}
file_num = 0- 使用字典推导式初始化数据容器:dic =
{key: [] for key in [...]}保证字段对齐
第四步、处理文件,汇总信息
for file in path.glob('*.pdf'):
with pdfplumber.open(file) as pdf:
for page in pdf.pages:
pdf_text = page.extract_text()
……-
path.glob(‘*.pdf’):获取path路径下所有的pdf格式文件: -
with pdfplumber.open(file) as pdf:使用pdfplumber模块打开文件。 -
for page in pdf.pages:遍历每一页。 -
page.extract_text():获取每一页的文本内容 -
提取的相应内容后写入dic字典。 -
except Exception as e:异常处理机制,确保单个文件出错后不会中断整体流程。
第五步、保存信息,显示结果
df = pd.DataFrame(dic)
df.to_excel(f"{path}/发票汇总.xlsx", index=None)
e_t=time.time()
print(f"共处理了{file_num}张发票\n用时{e_t-s_t:.2f}秒")-
首先把字典写入pd.DataFrame,然后保存到为{path}/发票汇总.xlsx,最后显示处理的结果和运行时长。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END







![表情[nanguo]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/nanguo.gif)
![表情[haobang]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/haobang.gif)
![表情[shuai]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/shuai.gif)
![表情[deyi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/deyi.gif)
![表情[chi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/chi.gif)



暂无评论内容