

![图片[1]-Python高效办公:2秒搞定文件夹下所有 pdf 的图片提取,告别手动截图的崩溃时刻-寻找资源网](http://img.seekresource.com/img/12243)
![图片[2]-Python高效办公:2秒搞定文件夹下所有 pdf 的图片提取,告别手动截图的崩溃时刻-寻找资源网](http://img.seekresource.com/img/12244)
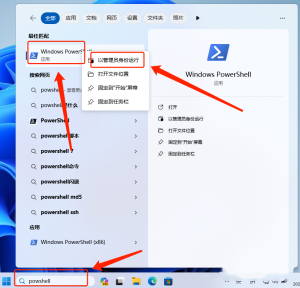
痛点:PDF里的图片怎么导出?
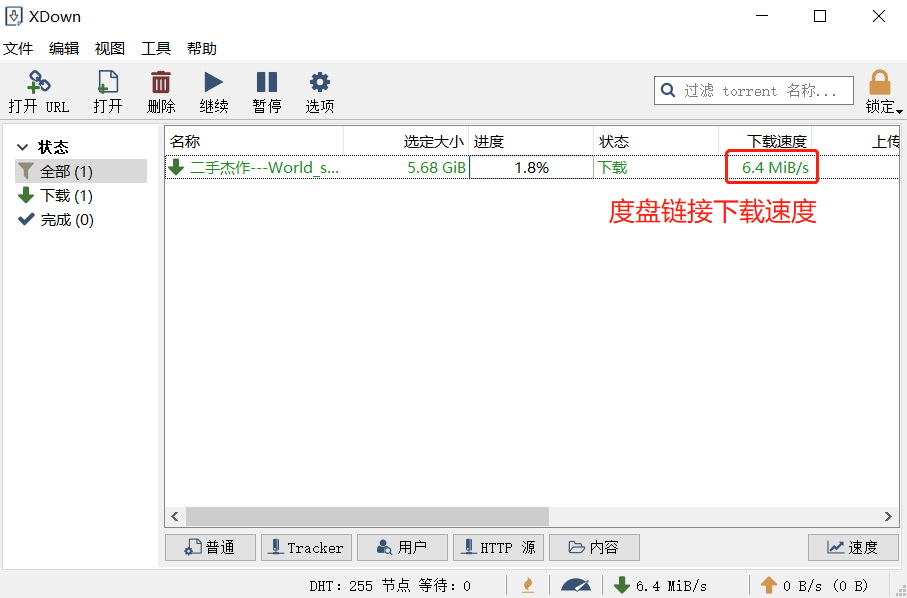
假设你有一个文件夹,里面存放着多个PDF文件,每个文件中都有若干张照片。如果你需要手动提取这些照片,那么你可能需要打开每一个PDF文件,一张一张地复制粘贴图片,然后保存到相应的文件夹中。这是一位网友的困惑。文件夹内的pdf文档中保存着许多证件照片,要求保存到本地电脑上。传统的手工操作方式是:逐个打开PDF文件 → 找到图片位置 → 右键点击保存图片 → 重命名图片 → 选择保存路径,右击没有反应,甚至需要使用截图工作,一张一张的截图,再新建文件夹分类保存……如此循环往复,不仅耗时耗力,还容易出错。
![图片[3]-Python高效办公:2秒搞定文件夹下所有 pdf 的图片提取,告别手动截图的崩溃时刻-寻找资源网](http://img.seekresource.com/img/12245)
方案:Python一键批量提取PDF图片
其实这种重复性的办公任务,用 Python 写几行代码就能轻松搞定。亲测处理 8 个文档 88 张照片,只用了 2.1 秒,效率直接拉满!
import fitz # PyMuPDFfrom PIL import Imagefrom pathlib import Pathimport ioimport time
start_time = time.time() # 记录开始时间path = Path(r"E:\例子\pdf提取照片") # PDF所在文件夹路径file_count = image_count = 0 # 统计处理的文件数和图片数
for file in path.glob("*.pdf"): # 遍历所有PDF文件 file_count += 1 folder = file.parent / file.stem # 创建同名文件夹(不含.pdf后缀) folder.mkdir(exist_ok=True) # 如果文件夹不存在,则创建
with fitz.open(file) as pdf: # 打开PDF文件 for page_num, page in enumerate(pdf, 1): # 遍历每一页(从1开始) images = page.get_images(full=True) # 获取当前页所有图片 image_count += len(images) # 统计图片总数
for img_id, img_info in enumerate(images, 1): # 遍历当前页的每张图片 img_data = pdf.extract_image(img_info[0]) # 提取图片数据 img = Image.open(io.BytesIO(img_data["image"])) # 转换为PIL图片对象 img.save(folder / f"第{page_num}页第{img_id}张图片.{img_data['ext']}") # 保存图片
print(f"共处理{file_count}个文件\n已提取{image_count}张照片\n用时{time.time() - start_time:.2f}秒")一键运行,结果秒成:
![图片[4]-Python高效办公:2秒搞定文件夹下所有 pdf 的图片提取,告别手动截图的崩溃时刻-寻找资源网](http://img.seekresource.com/img/12246)
解析:小白也能看懂
1. 导入必要的库
import fitz # PyMuPDF,用于读取PDF和提取图片
from PIL import Image # Python图像处理库,用于保存图片
from pathlib import Path # 更强大的路径管理(替代os.path)
import io # 处理二进制数据流import time # 计算运行时间fitz(PyMuPDF):专门用来处理PDF,可以提取文字、图片、表格等。PIL(Pillow):Python最常用的图像处理库,用于保存图片。Path:比os.path更现代的路径管理方式,代码更简洁。
2. 记录时间和设置路径
start_time = time.time() # 记录脚本开始运行的时间(用于计算总耗时)
path = Path(r"E:\pdf提取照片") # 设置PDF所在的文件夹路径
file_count = image_count = 0 # 初始化统计变量time.time():记录脚本运行时间,方便计算效率。Path(r"..." ):使用Path对象管理路径,比字符串拼接更安全。
3. 遍历PDF文件
for file in path.glob("*.pdf"): # 查找当前文件夹下所有PDF文件
file_count += 1 # 统计处理的PDF文件数量
folder = file.parent / file.stem # 新建同名文件夹(不含.pdf后缀)
folder.mkdir(exist_ok=True) # 如果文件夹不存在,则创建path.glob("*.pdf"):查找当前文件夹下所有.pdf文件。file.stem:获取文件名(不含扩展名),比如example.pdf→example。folder.mkdir(exist_ok=True):如果文件夹不存在,就自动创建,避免报错。
4. 提取PDF中的图片
with fitz.open(file) as pdf: # 打开PDF文件
for page_num, page in enumerate(pdf, 1): # 遍历每一页(从1开始)
images = page.get_images(full=True) # 获取当前页所有图片
image_count += len(images) # 统计图片总数
for img_id, img_info in enumerate(images, 1): # 遍历当前页的每张图片
img_data = pdf.extract_image(img_info[0]) # 提取图片数据
img = Image.open(io.BytesIO(img_data["image"])) # 转换为PIL图片对象
img.save(folder / f"第{page_num}页第{img_id}张图片.{img_data['ext']}") # 保存图片fitz.open(file):打开PDF文件,返回一个可遍历的页面对象。page.get_images(full=True):获取当前页的所有图片信息(包括图片ID、位置等)。pdf.extract_image(img_info[0]):提取图片的二进制数据(img_data["image"]是原始图片字节)。Image.open(io.BytesIO(...)):把二进制数据转换成PIL能处理的图片对象。img.save(...):保存图片,文件名格式为第X页第Y张图片.扩展名(如第1页第1张图片.jpg)
5. 输出统计结果
print(f"共处理{file_count}个文件\n已提取{image_count}张照片\n用时{time.time() - start_time:.2f}秒")-
time.time() - start_time:计算脚本运行总时间,单位是秒。 -
:.2f:保留2位小数,让时间显示更清晰。
通过使用Python和相关的库,我们可以大大简化从PDF文件中提取图片的过程。这种方法不仅提高了工作效率,还减少了人为错误的可能性。
看完不过瘾,那就自己发一篇吧!© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END







![表情[nanguo]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/nanguo.gif)
![表情[haobang]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/haobang.gif)
![表情[shuai]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/shuai.gif)
![表情[deyi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/deyi.gif)
![表情[chi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/chi.gif)



暂无评论内容