

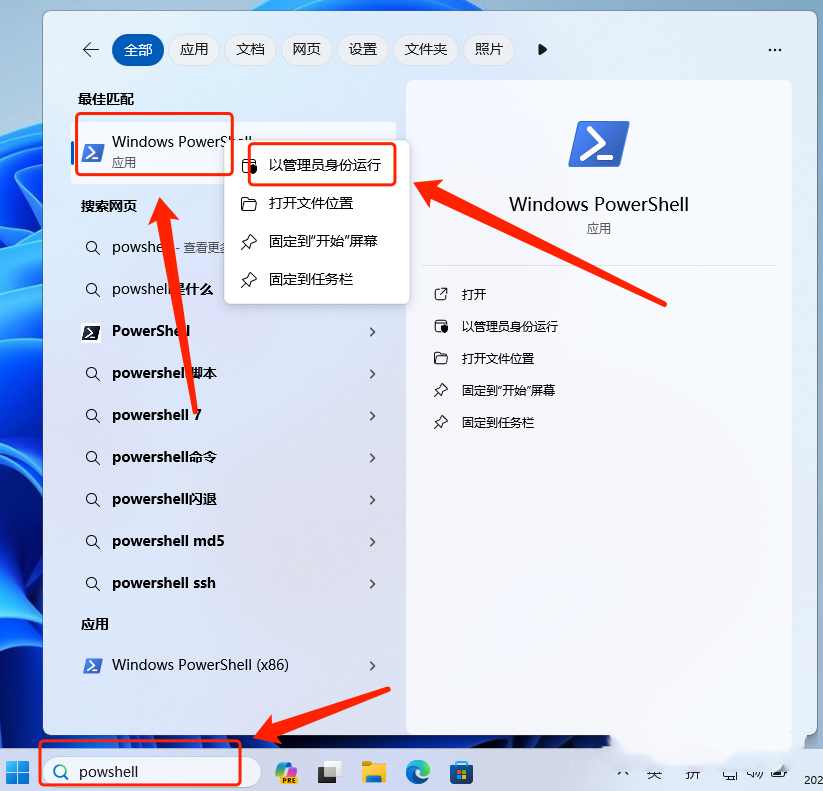
From:导师让我试试,有关武汉大学杨女士的论文的宗教场所数据爬取和分析部分进行复现。老师已经给出了初步的思路。老师的代码是selumium+Xpath。我想试试playwright,据说这个比selenium简单。
说干就干,我们就来复现下数据爬取过程。
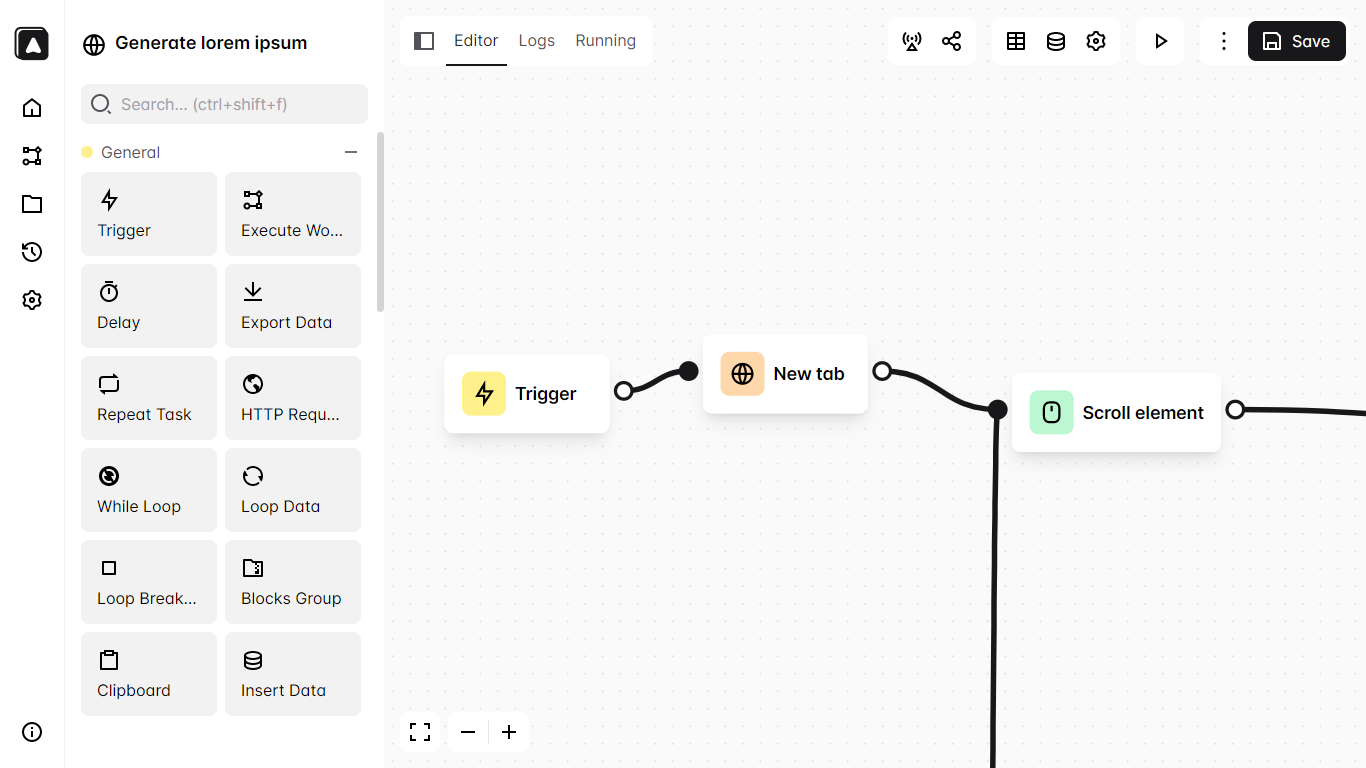
本文目录如下:
![图片[1]-使用playwright爬取动态加载数据,检验武大杨某某论文-寻找资源网](http://img.seekresource.com/img/12066)
Why playwright
Playwright 比传统爬虫工具(如Requests+BeautifulSoup)更适合处理动态渲染的网站,需要交互的页面(比如,需要点击/滚动等)复杂认证流程的网站。
playwright库爬虫基本步骤
playwright库主要是用来进行测试,我们如何使用playwright库爬虫呢?
1. 安装 Playwright
pip install playwright
playwright install # 安装浏览器驱动2. 基础爬取流程
fromplaywright.sync_apiimportsync_playwright
defscrape_data():
withsync_playwright() asp:
# 启动浏览器(Chromium/Firefox/WebKit)
browser = p.chromium.launch(headless=False) # headless=False可见浏览器
page = browser.new_page()
# 访问目标网页
page.goto("https://example.com", wait_until="networkidle")
# 等待元素加载
page.wait_for_selector("table#data")
# 提取数据
rows = page.query_selector_all("table tr")
forrowinrows:
print(row.inner_text())
browser.close()
scrape_data()3. 关键功能locator
- 元素定位:
page.locator("css=button.submit") # CSS选择器
page.locator("text=Login") # 文本定位
page.locator("xpath=//div[@id='content']") # XPath- 数据提取:
# 获取文本
element.inner_text()
# 获取属性
element.get_attribute("href")
# 获取表格数据
cells = row.query_selector_all("td")- 分页处理:
whileTrue:
# 提取当前页数据...
next_btn = page.locator("text=下一页")
if"disabled"innext_btn.get_attribute("class"):
break
next_btn.click()
page.wait_for_selector("#tbody-body tr")- 反爬应对:
context = browser.new_context(
user_agent="Mozilla/5.0...",
proxy={"server": "http://proxy:port"}
)playwright执行网页操作的2种方式
打开网页有2种方式,一种是使用其常规的API,一种是异步API。同步和异步 API 在功能实现上完全一致,主要区别体现在编程模型和执行效率上。
至于需要选择哪种,以下来自DeepSeek
- 建议使用同步API的场景:
简单脚本或一次性任务
已有代码库使用同步架构
开发者不熟悉异步编程
需要与Selenium等传统工具混用 - 建议使用异步API的场景:
高并发爬虫(同时控制10+浏览器实例)
需要与现有异步系统(如FastAPI服务)集成
涉及大量网络IO等待(如自动翻页抓取)
需要实现复杂交互流程(多页面并行操作)
同步API示例
先来看同步API的简单示例
fromplaywright.sync_apiimportsync_playwright, Playwright
defrun(playwright: Playwright):
# 使用 WebKit 浏览器引擎
webkit = playwright.webkit
# 启动浏览器
browser = webkit.launch()
# 创建一个新的浏览器上下文
context = browser.new_context()
# 打开一个新的页面
page = context.new_page()
# 导航到指定的 URL
page.goto("https://example.com")
# 截取页面截图并保存
page.screenshot(path="screenshot.png")
# 关闭浏览器
browser.close()
withsync_playwright() asplaywright:
# 调用 run 函数执行浏览器操作
run(playwright)这个代码的意思就是打开https://example.com网站,拍个网站照片,存到当前路径下,命名screenshot.png。
这是官网示例,可以直接运行。
异步API示例
代码如下
importasyncio
fromplaywright.async_apiimportasync_playwright, Playwright
# 定义一个异步函数,用于使用 Playwright 进行网页操作
asyncdefrun(playwright: Playwright):
# 使用 WebKit 浏览器引擎
webkit = playwright.webkit
# 启动浏览器
browser = awaitwebkit.launch()
# 创建一个新的浏览器上下文
context = awaitbrowser.new_context()
# 打开一个新的页面
page = awaitcontext.new_page()
# 导航到指定的 URL
awaitpage.goto("https://example.com")
# 截取页面截图并保存
awaitpage.screenshot(path="screenshot3.png")
# 关闭浏览器
awaitbrowser.close()
# 定义主异步函数,用于启动 Playwright 并调用 run 函数
asyncdefmain():
asyncwithasync_playwright() asplaywright:
# 调用 run 函数
awaitrun(playwright)
# 使用 asyncio 运行主函数
asyncio.run(main())也是同样的作用,区别在于需要显式使用 async/await 语法,同步API只需要用with语句来管理页面监测实例,显得更加简单。
因为同步API比较简单,我们先用同步API演示下面的步骤
提取数据
首先,导航到指定的网址。
这里,我们就是到国家宗教事务管理局的宗教活动场所基本信息查询系统。
![图片[2]-使用playwright爬取动态加载数据,检验武大杨某某论文-寻找资源网](http://img.seekresource.com/img/12067)
page.goto("https://www.sara.gov.cn/resource/common/zjjcxxcxxt/zjhdcsjbxx.html")然后,我们可以看到这网页是动态加载的表格数据,网页地址不会随着表格页面而变化,所以,我们要先定位到让这个表格动态加载的按钮上。也就是说只要这个表格内容加载出来了,就开始爬取数据。
那么,要先确定定位哪个作为加载?
定位数据
详见下图。
![图片[3]-使用playwright爬取动态加载数据,检验武大杨某某论文-寻找资源网](http://img.seekresource.com/img/12068)
网页右键——检查,也可以直接按F12进入开发者工具页面,然后ctrl+f搜索表格内的文字内容,比如“广济寺”,定位到广济寺文本所在html的位置,找到他是在<td>标签下的,再往上一级元素回溯是<tr>标签,但是<tr>标签是每行,所以还需要回溯到整个表格的标签,可以发现是<tbody>标签,而且这个标签有id,很好定位。
编写如下代码——
# 等待表格加载完成
page.wait_for_selector("#tbody-body tr", state="attached")让deepseek详细解释一下这里wait_for_selector函数参数的意义:
CSS 选择器 “#tbody-body tr”:
#tbody-body:选择 id 为 tbody-body 的元素。这个元素通常是一个 table 元素。tr:选择该 table 元素中的所有 tr(table row)元素。
等待条件 state=”attached”:
state=”attached”:表示等待选定的元素被附加到 DOM 中。这意味着 Playwright 会等待直到 #tbody-body 表格中的至少一个 tr 元素出现在页面的 DOM 中。这个条件确保在抓取数据之前,表格已经加载完成,避免抓取到不完整或未加载的数据。
页面结构如下
<tbodyid="tbody-body">
<tr>
<td>宗教1</td>
<td>派别1</td>
<td>场所名称1</td>
<td>地址1</td>
</tr>
<tr>
<td>宗教2</td>
<td>派别2</td>
<td>场所名称2</td>
<td>地址2</td>
</tr>
<!--更多tr元素-->
</tbody>那么,将表格里面的数据提取出来, 需要用到query_selector_all函数,参数填写”#tbody-body tr”,就是遍历<tbody>标签中的所有tr(table row)元素。
rows = page.query_selector_all("#tbody-body tr")
forrowinrows:
cells = row.query_selector_all("td")
print(cells[0].inner_text().strip()) # 佛教遍历全部行列
# 等待表格加载完成
page.wait_for_selector("#tbody-body tr", state="attached")
all_data = []
# 获取当前页数据
rows = page.query_selector_all("#tbody-body tr")
forrowinrows:
cells = row.query_selector_all("td")
iflen(cells) >= 4:
all_data.append(
{
"宗教": cells[0].inner_text().strip(),
"派别": cells[1].inner_text().strip(),
"场所名称": cells[2].inner_text().strip(),
"地址": cells[3].inner_text().strip(),
}
)存储数据
我们用with语句来将数据存储进入religious_sites_all.csv。
# 保存结果
withopen("religious_sites_all.csv", "w", encoding="utf-8-sig") asf:
f.write("宗教,派别,场所名称,地址\n")
foriteminall_data:
f.write(
f"{item['宗教']},{item['派别']},{item['场所名称']},{item['地址']}\n"
)如何使用python读写操作可以查看。
翻页提取数据
动态数据翻页爬取(下一页)
上述代码目前只是爬取了当前页的。所以还需要处理翻页后爬取的内容。
如何让代码代替人点击鼠标实现翻页呢?
我们可以看到有“下一页”的按钮
![图片[4]-使用playwright爬取动态加载数据,检验武大杨某某论文-寻找资源网](http://img.seekresource.com/img/12069)
我们只需要使用locator()进行定位,参数也很简单,就是html里面的文本,我们复制这一行所有元素。可以看到<li>标签下就这一个文本。
<liclass="xl-nextPage">下一页</li>所以,写下面这样的代码,就可以定位到了。
小技巧:如果不会定位,直接复制粘贴全部元素,让deepseek等AI给你写出定位代码。
# 定位“下一页”按钮
next_button = page.locator("text=下一页")模拟鼠标点击按钮
然后,使用click()直接点击
next_button.click()page.locator()支持 CSS 或 XPath的语法进行定位并点击
page.locator("css=button").click()
page.locator("xpath=//button").click()
page.locator("button").click()
page.locator("//button").click()点击后等下一页的数据加载出来就继续进行数据提取。
page.wait_for_selector("#tbody-body tr", state="attached")最后一页
到了最后一页,我们需要停止爬取。
我们观察最后一页的元素状态,会发现,到了最后一页,其“下一页”按钮的元素是这样的
<liclass="xl-nextPage xl-disabled">下一页</li>与前面的不一样。
<liclass="xl-nextPage">下一页</li>所以,我们只需要判断<li>标签的元素,只要属性有“xl-disabled”就知道是最后一页。
# 定位包含“下一页”文本的 li 元素
next_button_li = page.locator("text=下一页").first
print(next_button_li) # <li class="xl-nextPage">下一页</li>
# 检查 li 元素的类名
li_class = next_button_li.get_attribute("class")
print(f"下一页 li 元素的类名: {li_class}")
if"xl-disabled"inli_class:
print("已是最后一页")全部代码
用while循环语句,让每一页爬取后都打印到控制台上,方便我们查看进度。
为避免错误,让deepseek给增加了try-except语句进行优化。
以下是本文的完整代码:
fromplaywright.sync_apiimportsync_playwright, Playwright
defrun(playwright: Playwright):
# 使用Chromium引擎(兼容性更好)
browser = playwright.chromium.launch() # 调试时显示浏览器 #headless=False
context = browser.new_context()
page = context.new_page()
# 导航到目标URL
page.goto(
"https://www.sara.gov.cn/resource/common/zjjcxxcxxt/zjhdcsjbxx.html",
wait_until="networkidle",
)
# 等待表格加载完成
page.wait_for_selector("#tbody-body tr", state="attached")
all_data = []
page_num = 1
whileTrue:
print(f"正在处理第 {page_num} 页...")
# 获取当前页数据
rows = page.query_selector_all("#tbody-body tr")
forrowinrows:
cells = row.query_selector_all("td")
iflen(cells) >= 4:
all_data.append(
{
"宗教": cells[0].inner_text().strip(),
"派别": cells[1].inner_text().strip(),
"场所名称": cells[2].inner_text().strip(),
"地址": cells[3].inner_text().strip(),
}
)
# 调试:打印当前页数据条数
print(f"第 {page_num} 页获取到 {len(rows)} 条数据")
# 尝试翻页
try:
# 定位包含“下一页”文本的 li 元素
next_button_li = page.locator("text=下一页").first
print(next_button_li) # <li class="xl-nextPage">下一页</li>
# 检查 li 元素的类名
li_class = next_button_li.get_attribute("class")
print(f"下一页 li 元素的类名: {li_class}")
if"xl-disabled"inli_class:
print("已是最后一页")
break
# 定位“下一页”按钮
next_button = next_button_li.locator("text=下一页")
# 使用JavaScript直接点击
next_button.click()
# 等待新数据加载
page.wait_for_selector("#tbody-body tr", state="attached")
page_num += 1
exceptExceptionase:
print(f"翻页时出现错误: {str(e)}")
break
# 保存结果
withopen("religious_sites_all.csv", "w", encoding="utf-8-sig") asf:
f.write("宗教,派别,场所名称,地址\n")
foriteminall_data:
f.write(
f"{item['宗教']},{item['派别']},{item['场所名称']},{item['地址']}\n"
)
print(f"共获取 {len(all_data)} 条数据,已保存到 religious_sites_all.csv")
browser.close()
withsync_playwright() asplaywright:
run(playwright)经过近半小时的爬取,数据得到了,我们再进行清洗。
把那些很明显不对的数据删除。
比如,下面这些:
![图片[5]-使用playwright爬取动态加载数据,检验武大杨某某论文-寻找资源网](http://img.seekresource.com/img/12070)
最终得到42445条数据。
![图片[6]-使用playwright爬取动态加载数据,检验武大杨某某论文-寻找资源网](http://img.seekresource.com/img/12071)
因为是杨某某需要分省份数据,所以还需要将宗教场所的地址按省统计,请继续看下文。
杨某某论文分析
数据拿到了,参考老师给出的思路,来看她论文这里的明显问题。
首先声明,我这是就事论事,不掺杂个人感情。
疑点一:工作量大的数据爬取和清洗过程一带而过
下面是杨某某使用宗教场所进行论证的文章内容:
![图片[7]-使用playwright爬取动态加载数据,检验武大杨某某论文-寻找资源网](http://img.seekresource.com/img/12072)
因为是分省的人均寺庙数(道观数),复现数据爬取完毕后,我得再次清洗为分省数据。
核心的代码如下。
# 提取省份
foritemindata:
# 从字典中提取地址字段
address = item["地址"]
item["省份"] = extract_province(address)
print(f"场所名称: {item['场所名称']}, 省份: {item['省份']}")
# 输出结果到文件
withopen("religious_sites_with_province.csv", "w", encoding="utf-8-sig") asf:
# 写入表头
f.write("宗教,场所名称,省份,地址\n")
# 按行写入数据
foritemindata:
f.write(
f"{item['宗教']},{item['场所名称']},{item['省份']},{item['地址']}\n"
)然后发现有一千多条地址没有省级地址。这种情况下可以只好让AI帮忙了。
![图片[8]-使用playwright爬取动态加载数据,检验武大杨某某论文-寻找资源网](http://img.seekresource.com/img/12073)
一千多个数据需要清洗,要是自己手动得花不少时间,所以直接用deepseek的API来补,生成markdown表格。
因为我用的硅基流动的免费API有点慢,经过近半小时的调试,最后很多地名生成了所在省份,还是有些没有补出来。
![图片[9]-使用playwright爬取动态加载数据,检验武大杨某某论文-寻找资源网](http://img.seekresource.com/img/12074)
后续的还是需要手动调整。
算上我编辑这篇文章的时间,10小时过去了。
所以,她这么牛,为什么不细说自己工作量?
疑点二:没有传统现代的具体划分值
找到每个省的人口数据,我们可以得到如下数据
![图片[10]-使用playwright爬取动态加载数据,检验武大杨某某论文-寻找资源网](http://img.seekresource.com/img/12075)
![图片[11]-使用playwright爬取动态加载数据,检验武大杨某某论文-寻找资源网](http://img.seekresource.com/img/12076)
杨某某没有说人均各省份人均寺庙数(道观数)得出来之后,按照以什么值划分传统观念开放与现代。
真不严谨啊。那我按照他图里的情况,山西传统观念传统,辽宁现代,划分应该基于0.18-0.21之间。
疑点三:道观替代了宗教场所的概念
先不说是否可以根据人均道观数(寺庙数)来衡量地区思想传统程度。
下面是杨某某使用宗教场所进行论证的文章内容:
![图片[12]-使用playwright爬取动态加载数据,检验武大杨某某论文-寻找资源网](http://img.seekresource.com/img/12077)
她论文里,明显是用道观数替代了宗教场所。
在我复现的数据中,西藏0个道观,1784个寺庙。那要是人均道观数,西藏不是妥妥的“超现代地区”。
而且,在我42445条数据中,道观数据只有8347,这么明显的差异,她没发现么。
结论:杨某某根本没有实际数据
总结一下,要是真进行了爬取、清洗和数据处理过程,正常情况下一定会写出来体现工作量的,也会说自己按什么数值划分划分传统观念开放与现代地区的,更不会犯用道观数替代了宗教场所数这样的错误。
有理由相信,杨某某根本没有实际数据,所谓的爬取估计就是借鉴了31个省市传统/现代的分类的结果而已。
看完不过瘾,那就自己发一篇吧!








![表情[nanguo]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/nanguo.gif)
![表情[haobang]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/haobang.gif)
![表情[shuai]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/shuai.gif)
![表情[deyi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/deyi.gif)
![表情[chi]-寻找资源网](http://www.seekresource.com/wp-content/themes/zibll/img/smilies/chi.gif)



暂无评论内容